“New” is a temporary adjective; one that will disappear when the original disappears.
This is especially true when applied to software.
The “New UI” becomes just the UI. The “New Reports” become the reports. Any “New Experience” will fade into the experience.
Your current customers won’t remember “new”. Customers that join after the release will never know about “new” because they never experienced the “old”.
The only ones who know, or care, about “new”, or “old” are the people who built and maintain the code.
“New” versions of existing services aren’t new, they’re the same service, with the same limitations. Truly new experiences have new names that speak to customer value.
If you are talking about “New Service”, you’re not talking to the customer, you’re talking to yourself. New is temporary, take the time to figure out what you're really building before it becomes just the current version of what you had before.
Infrastructure changes aren't captured by unit tests, so how do you test them before going into production? In this episode Isaac and I welcome back guest Rob Gonnella to discuss testing infrastructure changes. Rob shares his experiences in developing local testing environments, engaging developers, and identifying bugs through end-to-end tests.
If you're thinking about changing things outside of your code and wondering how to test, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
When management agrees to rewrite software, they inevitably split the existing team in two - Team Rewrite and Team Maintenance. Team Rewrite is in charge of creating a brand new system that recreates everything useful and good about the legacy system. Team Maintenance is in charge of maintaining the legacy system until Team Rewrite completes the rewrite. Everyone wants to be on Team Rewrite and no one wants to stay on Team Maintenance; everyone is wrong.
The benefits of Team Rewrite are obvious, you get to write new code without all the horrors of the legacy system. You’ll use the latest technology! You’ll do things the right way! Your work won’t be in production, so you won’t have production incidents! No angry customers! The list goes on.
The benefits of Team Maintenance aren’t clear. You get to work in the horrible legacy system. The system that is so bad, so unfixable, that management has agreed to a rewrite. Plus you’ll be responsible for incidents and outages! Why would anyone join Team Maintenance?
It’s not glamorous, but the people maintaining the legacy system are critical. The members of Team Rewrite contribute to theoretical future value, Team Maintance’s work supports customers today. If things go badly with the rewrite, and usually do, the entire rewrite team can be fired. The maintenance team remains critical so long as the legacy system lives.
Team Maintenance is also two kinds of opportunity.
First, is the opportunity to clean up the legacy system. The legacy system doesn’t have to continue to be terrible. It’s likely that most or all of the people who said it couldn’t be fixed are now on Team Rewrite. Everyone left is committed to working on it for the duration. It’s a great time to clean things up; not to save the system, but for your own sakes. Very quickly the legacy system won’t be horrible. It may never be great, but you can work on it sobbing.
The second opportunity is new features.
Customer needs don't stop just because there’s a rewrite going on. Management will limit the new features so that the rewrite isn’t trying to hit a moving target. You’ll only be working on the most important, most critical, and most impactful features. And you’ll get to work on the critical features, because you’re Team Maintenance.
Does this mean you join Team Maintenance rooting for Team Rewrite to fail? Not at all! If Team Rewrite succeeds that’s also great for you. You’ve shown that you’re a selfless team player - you took on the work that no one else wanted! Seize the opportunities that come along and you’ll show that you can be trusted to improve your team and deliver critical features.
When a rewrite comes along, your best move is to join the maintenance team. Volunteering for Team Maintenance is safer, comes with more opportunity, and brings you to management’s attention. Rewrites usually fail and Team Rewrite leaves the company. Join Team Maintenance for career growth!
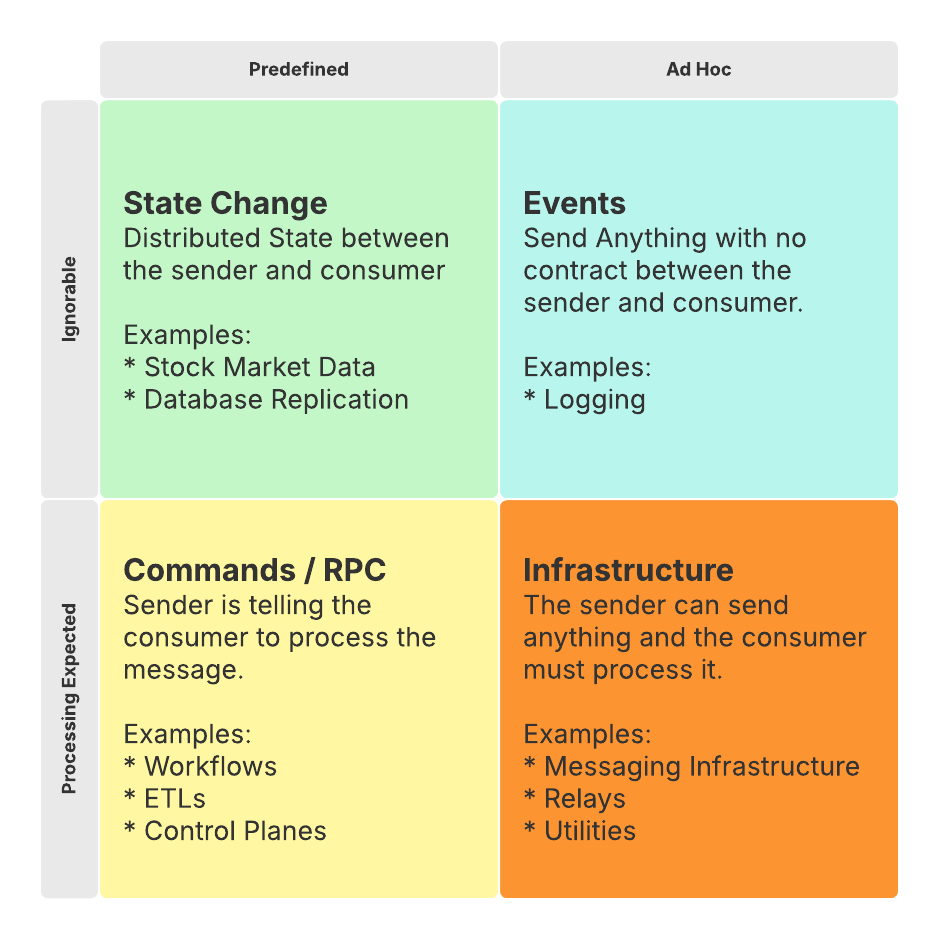
Whether you use Kafka, RabbitMQ, or even SMS, messaging infrastructure is neutral about what you are sending and why. It is up to you, the developer, to decide on the contract between the producer and consumer of your messages.
There are 2 main considerations:
Are your messages Predefined or Ad Hoc?
Are your messages Ignorable or is Processing Expected?
It is critical that you set appropriate expectations for your messaging structure. Otherwise, you’ll end up with the Command-Event Anti-Pattern.
Event Pattern - Ad Hoc & Ignorable
The Event Pattern has the least structure and fewest guarantees: You publish events in any format you want, and they may or may not get consumed.
The publisher has no expectations about whether the consumer cares about the event. The consumer has minimal expectations about the event’s structure or data.
Generally, the only time to use the Event Pattern is with logging.
Logs are minimally structured. You want enough structure for your logs to get consumed by your observability platform, but not enough that it is difficult to add logs in the code.
Log messages may or may not be consumed. Most logging systems determine whether to log based on severity settings. In production, ERROR will almost always be on, while DEBUG will almost always be off. Those are run time decisions though, the code doesn’t have any expectations.
State Change Pattern - Structured & Ignorable
With the State Change Pattern each event represents a change to the state of the system. The messages are highly structured so that the consumer understands how the state just changed. However, there is no guarantee that anyone will consume the message, and no guarantees about what the consumers will do about the change.
The State Change Pattern is extremely powerful, and difficult to do correctly.
The largest State Change Messaging platforms publish market data from stock exchanges. Each message is either a new order, a canceled order, or an execution (trade). Trading software uses the data to determine current prices, build books, and do everything else needed to help stock traders make decisions.
The stock market (the publisher) doesn’t have any expectations about what the consumer (the trader) on the other end will do about each message.
A more technical example of State Change is database replication. The primary database publishes change events (called binlogs in Mysql) and the replicas database servers consume the messages to stay in sync. From the primary server’s perspective it doesn’t matter if there are 0 replicas or 100. Or if the replicas are only doing partial replication. The primary server will still publish all changes.
Command Pattern - Structured with Processing Expected
In the Command Pattern, or RPC (Remote Procedure Call) each message represents an attempt to run a command or execute work. The important difference from the Event Pattern and State Change Pattern is that the Command Pattern has expectations about the consumer’s behavior.
The publisher has the expectation that all of the messages will be processed by the consumers. Some implementations allow the publisher to know about the consumers and direct specific messages to specific consumers, but that isn’t a requirement.
Background workers, control planes, and job queues are some of the places you would use the command pattern.
Infrastructure - Ad Hoc with Processing Expected
The final quadrant, Infrastructure, describes messaging platforms themselves. The publisher can send whatever they want, and the platform will process it.
Because this pattern describes messaging infrastructure, there are few uses for it ON messaging infrastructure. Having RabbitMQ tunnel through Kafka might be an interesting project, but it wouldn’t be very useful.
Beware The Command-Event Anti-Pattern
If you aren’t intentional about your messaging pattern, you will inevitably end up with the Command-Event Anti-Pattern. This is when you have multiple, loosely defined, message structures, some of which place processing expectations on the consumer.
The Command-Event pattern makes it easy for incorrect messages to clog up the system. It creates confusion about which messages can be ignored, and which must be processed. You will have a muddled mess and a long hard transition to separate your message types.
Conclusion - Be Intentional About Your Messages
Remember, the messaging infrastructure will accept any structure, or no structure. It is concerned with delivery, not processing. So long as every consumer gets every message that it is supposed to, your infrastructure is working properly.
It is up to you, the developer, to add expectations.
How much structure do your messages need? Can they be skipped? Depends on what problem you are trying to solve! If you go forward without deciding you’ll end up with a mess known as the Command-Event anti-pattern.
If you’ve got a mess, you can fix it iteratively! Never try a rewrite! Iteratively separate your messages onto new, problem specific, streams.
Never Rewrite is going analog! Out of 2000 minutes over the last two years we think we've got plenty of content to coalesce it into a book. If you have a rewrite story to share, now's your chance to get forever immortalized in the podcast hosted by two randos.
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
Isaac and I are excited to announce that we are taking our podcast to a book!
Never Rewrite: The Low Risk Guide To Modernizing Your Legacy Software is for everyone who maintains, or relies on, systems that you hate.
Systems that are poorly designed, unreliable, untestable, won’t scale, or make you tear your hair out. Where every change creates 2 new bugs. Systems that are so bad that they can’t be fixed.
Where it seems like the only option is to start over from scratch.
When it seems that you need a rewrite, you need Never Rewrite: The Low Risk Guide To Modernizing Your Legacy Software.
Because no one actually wants a rewrite -
Developers don’t want a rewrite, they want to work with well designed and tested code that doesn’t fight them every step of the way. They want to take pride and get joy from their work.
Managers don’t want a rewrite, they want the people they manage to be happy, for bug reports to be few, and for work to be delivered at a consistent pace.
Leadership doesn’t want a rewrite, they want to empower their people, have reliable systems, and consistent delivery.
If no one wants a rewrite, why does it seem like a reasonable solution? Because it seems like there are no other options.
We’re here to tell you that there is another way -
Never Rewrite will teach you how to modernize legacy software without a rewrite. The book will show you how rewrites destroy teams, increase turnover, and prevent growth. We will show you how to escape a rewrite in progress.
Along the way we share real stories of rewrite; from Sonos’ recent $500 million debacle, companies that paused new features for years, and projects that cost millions and never made it into production. Our case studies are full of lost opportunity, wasted money, and derailed careers.
If you’d like to learn more, please sign up to our mailing list and be the first to hear about our progress!
Why would anyone ever say yes to a proposal to stop all new work for 6 months so that the developers can recreate something that already exists? In this episode of NeverRewrite Isaac and I explore the motivations and expectations for a rewrite. Developers, IT leaders, product, marketing, finance, support, and customers have different outcomes in mind from the same rewrite. We explore the perceived benefits and harsh reality of rewrites - they often fail to deliver on any of their promises.
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
This article walks you through optimizing an import process. I’m going to lay out a simple SaaS db and api, discuss how imports emerge organically, and show you how to optimize for performance.
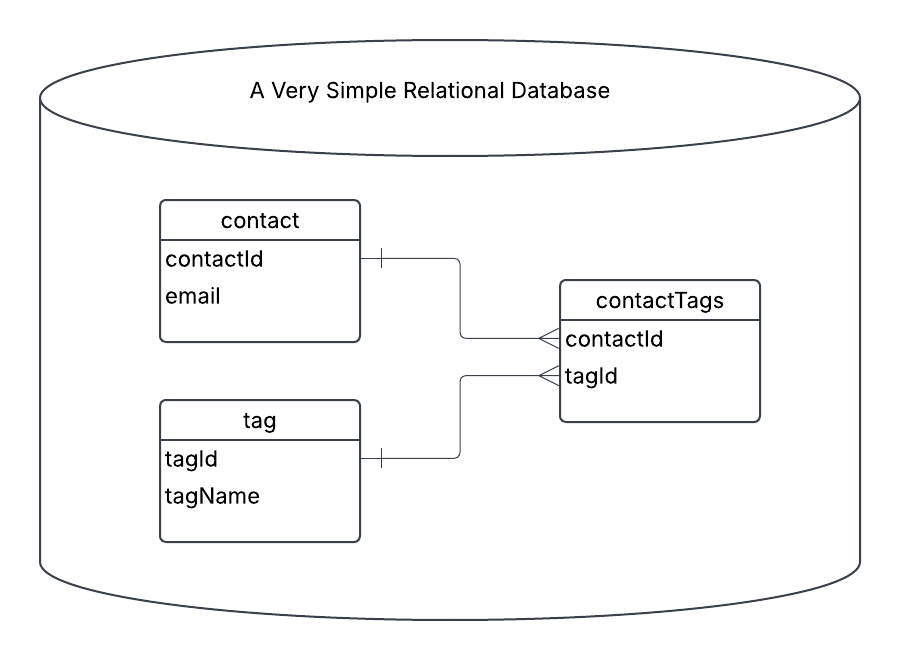
For the article, we are starting off with a simple CRM that lets you create email contacts, and add tags to them. This is a real, but very small, piece of functionality in all CRMs, and even most SaaS.
API First
Most SaaS start with basic CRUD abilities, an endpoint to create contacts, an endpoint to create tags, and an endpoint to associate tags with contacts. You
[POST] /api/contact - create the contact
[POST] /api/tag - create the tag
[POST[ /api/contact/{id}/tag - create the contactTag relationship
Simple and straightforward. Great for UIs. Cumbersome and clunky if you aren’t a programmer.
CSV Second
Since most people aren’t programmers, and most people can export their data to CSVs, “import data from a CSV” soon emerges.
Here’s our CSV header:
Email, tag1, tag2, …, tagN
Each line starts with an email address, and then 0->N tags that should be associated with the contact. To keep things simple we won’t be deleting any tags that are in the database, but not in the file.
When done well the customer’s file will be written somewhere like Amazon’s S3, and then processed asynchronously. The CSV processing code will be DRY and use the same code from the API.
For each line in the file:
Retrieve the existing contact’s id by email, or create a new contact
For each tag
Retrieve the existing tag’s id by name, or create a new tag
Insert contactId, tagId into the database, if it doesn’t already exist
The code to exercise these steps already exists.
[POST] /api/contact and Retrieve the existing contact’s id by email, or create a new contact run the same code.
[POST] /api/tag and Retrieve the existing tag’s id by name, or create a new tag are the second pair.
[POST[ /api/contact/{id}/tag and Insert contactId, tagId into the database, if it doesn’t already exist complete the functionality.
The emergent model is great because the only new functionality is the ability to store and process the CSV file. The business logic, how data actually gets inserted into the database, gets reused.
Big O, Performance, and Scalability
The algorithm described above has a Big O of O(n^2). For something like an import that’s not great, but it’s also not terrible.
O(n^2) doesn’t tell you much about the real world performance or scalability of the implementation. There are a few different implementations for the data access patterns which could result in wildly different performance characteristics.
In our simple example we look up the tagId in the database for each contact. This mirrors the access pattern for the API. But, we aren’t in the API, we’re in a long running process. We could store the tag-name-to-id information in a map in memory.
Adding an in-memory cache would limit step 2a to running once-per-tag instead of once-per-tag-per-contact. A file with a single tag per contact would save almost ⅓ of its calls. As the number of tags increased, the savings would increase towards ½ of the db calls.
Cutting the number of DB calls in half won’t change the Big O value, but it will greatly improve performance and reduce load on your DB.
Moving From Rows To Columns
The emergent model is great because it reuses code. One drawback is that it involves lots of trips to the database to do single inserts. Trips to the database over a network are relatively slow. Most databases are also optimized for fewer, larger writes.
Processing the CSV file row by row will always push you towards more, smaller, writes because the rows of the file will be relatively short.
Instead, let’s consider a “columnar” approach.
Instead of processing line by line and pushing it to the database, we’re going to sort the data in memory, and push the results to the database.
For simplicity, we will do two passes through the file.
Pass 1 looks very similar to the original process:
Retrieve the existing contact’s id by email, or create a new contact. Store the email/id relationship in a map.
For each tag, retrieve the existing tag’s id by name, or create a new tag. Store the tagName/id relationship in a map.
At the end of Pass 1, we have ensured that all contacts exist, and that all tags exist.
For Pass 2, we replace emails and tags with ids and build a single, large, insert statement like this:
Insert into contactTags (contactId, tagId) values
(1, 1), (1, 2), (1, 3),
(2, 1), (2, 3),
…
Again, simplifying and glossing over the entire subject of upserts, duplicate keys, etc. This post is dense enough as it is.
How Much Faster Is Going A Column At A Time?
In the real world the impact will vary based on the number of rows in the table, contention, complexity, indexes, and a whole host of variables.
Instead let’s look at it by the number of queries each option requires.
Let’s pretend we were inserting a file with 100 new contacts, and each contact had the same 5 tags.
API / Basic Import
We would insert the contact, then insert the tag, then the 5 contactTags.
That is 11 operations per row - 1 contact, 5 tags, 5 contactTags.
Over 100 rows that works out to 100 contact inserts, 5 tag inserts, 495 tag lookups, 500 contactTag inserts.
That’s 1,100 Operations
Import (or API) with tag caching between rows
Adding the in-memory tag cache greatly decreases the number of operations. We no longer need to do the redundant 495 tag lookups.
Now over the course of 100 rows it works out to 100 contact inserts, 5 tag inserts, 500 contactTag inserts.
That’s 605 Operations, at 45% reduction!
Columnar
Finally, we switched to a 2-pass columnar strategy. Instead of doing 500 contactTag inserts, we do a single insert with 500 clauses.
Now our 100 rows become 100 contact inserts, 5 tag inserts, 1 contactTag insert.
That’s 105 Small Operations and 1 Large Operation. That’s a 90% reduction from our initial version, and an 82% reduction from the improved version!
Reminder - that one large operation is going to take significantly longer than any one of the single inserts. You won’t see an 82-90% reduction in processing time. In the real world you would probably cut time by 50%, a mere 2x improvement!
The columnar work could be further optimized to be 1 large insert for contacts, 1 large tag insert, and 1 large contactTag insert. It is more complicated because we need to get the ids, but we could get it down to as little as 5 total db operations - 3 Large Inserts and 2 key lookups. I can cover the final technique in another post if there is interest.
Summary - Tradeoffs Make Columnar Fastest
Having your import process reuse the code from your API is a great way to start. Because of the code reuse the only thing you have to implement is the file handling. That keeps things simple and lets you get the feature out fast.
But, following your API’s code path is also going to be very inefficient and not scale well.
Changing strategies to favor fewer, larger, operations can reduce the number of operations by 80-90% and increase real world performance by 50% or more.
Rewriting and Iteratively Replacing software both end with the original software being completely replaced. Since the result is the same, it can be difficult to understand why Iterative Replacement, or TheeSeeShipping is so much more effective and less risky.
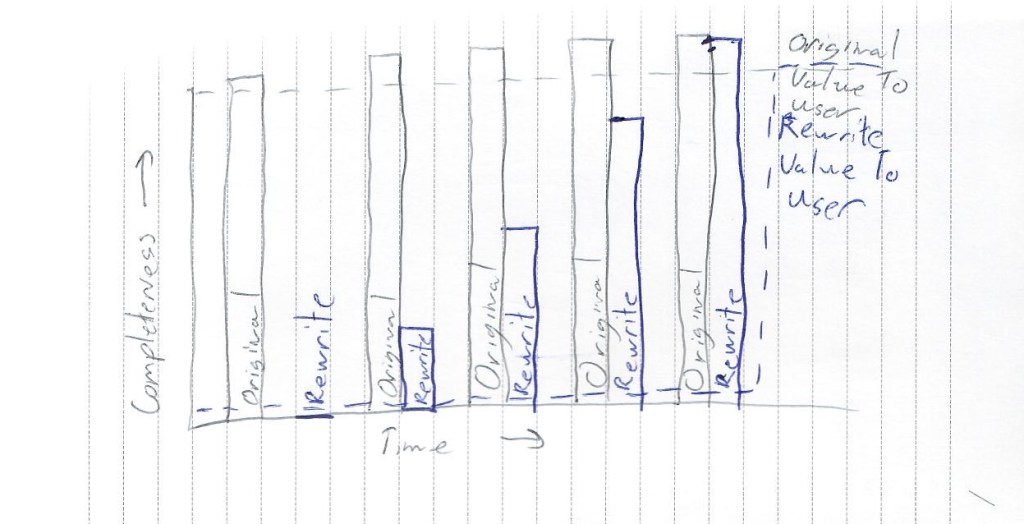
When you rewrite software you leave the original code alone and build new software that does the same thing, but better. You start with one piece of working code, build a second piece of working code, and then stop the first. To your users, the change happens all at once, at the end of the project.
With Iterative Replacement, you always have exactly one piece of working code. The “bad” parts are replaced one at a time, and go into production. At the end of every release, there is exactly one system, the one in production. User’s experience the change gradually over time and they will see value from the project all along the way.
Both paths end with the original code being 100% replaced. With replacement, you can see that customer value comes much earlier.
What the graphs don’t show is the risk of the project ending before the original code has been fully removed. If a rewrite stops before 100%, your users get nothing.
Rewrites are always more risky, because they set up an all or nothing dynamic.
Priority changes rarely align with projects finishing, and changes often result in throwing away work in progress. In this episode, Isaac and I discuss different work philosophies and styles that will protect your work, minimize loss, and keep you productive.
If you've ever stopped work on a project that was 90% complete and realized that it would never ship, this is the episode for you!h customer needs.
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!