Code can you tell you how something works, but it can't tell you how it is supposed to work. How can growing businesses keep track of how features are supposed to work? Especially over, growth, time and people when the way it should work keeps changing.
If you've ever looked at code and said "I see what it says, but I have no clue what it means", this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
Scaling bottlenecks choke SaaS growth. Bottlenecks can prevent you from onboarding customers fast enough, make supporting your largest customers impossible, and even leave you saying no to giant deals. Scaling issues impact your annual recurring revenue (ARR), net dollar retention (NDR), and customer lifetime value (CLTV). Imagine telling paying customers that they’ve grown too big and need to move to another platform! It is not only extremely frustrating, it weighs down all of your major metrics.
The rate at which you can onboard new customers is knowable. So is the maximum customer size that has delightful experiences. Customers don’t get too big overnight, they grow with you for years. You can write tools to discover the system maximums. Knowing the limits won’t prevent you from hitting them, but it will prevent you from being surprised.
Scaling bottlenecks are a form of tech debt; bottlenecks are the result of your past decisions, regardless of whether those decisions were intentional. Accidentally creeping up on the system’s limits requires not knowing where they are in the first place.
Do you know where the limits are? Was it not worth investigating because it wasn’t maxed out?
If you don’t know, you will end up turning away customers and limiting ARR growth. Capping customer size also caps CLTV. Saying goodbye to long term customers tanks your NDR and hurts your ARR.
All systems have bottlenecks. The only question is: How do you want to find them? You can seek them out, or you can find them in your bottom line.
My post about latency and throughput featured an extremely simplistic model to demonstrate that Latency and Throughput are independent. An astute reader called it a spherical cow, a model so over simplified that it is a bit ridiculous.
So, let’s deflate the cow, just a bit, and see how things hold up. I hope you like tables and cow jokes!
(Keenan Crane; GIF by username:Nepluno, CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons)
Chewing The Cud
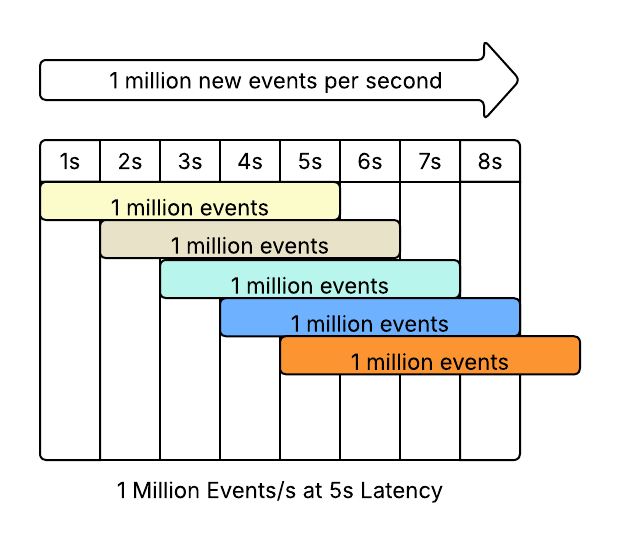
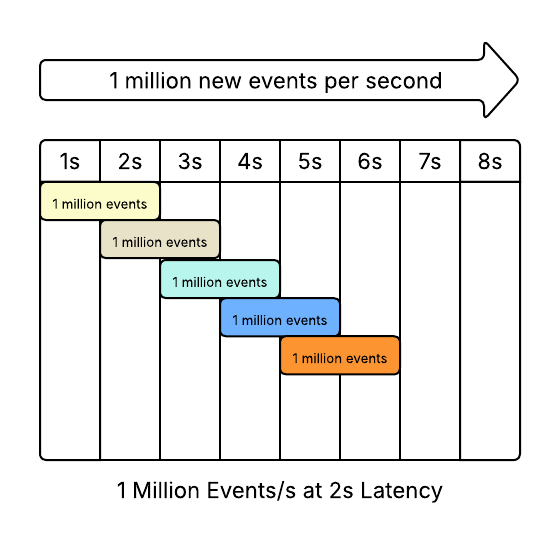
The original model was a streaming system that receives 1 million messages a second. Perfectly spherical.
There were two systems, one with 5s latency, one with 2s latency.
We will leave our processors completely spherical - they each process 100,000 events simultaneously. Our pipelines then look like this
5s Latency
Time
New Events/s
Process Instances
Events Being Processed
Throughput
Extra Capacity
1
1,000,000
50
1,000,000
0
4,000,000
2
1,000,000
50
2,000,000
0
3,000,000
3
1,000,000
50
3,000,000
0
2,000,000
4
1,000,000
50
4,000,000
0
1,000,000
5
1,000,000
50
5,000,000
1,000,000
0
6
1,000,000
50
5,000,000
1,000,000
0
7
1,000,000
50
5,000,000
1,000,000
0
8
1,000,000
50
5,000,000
1,000,000
0
2s Latency
Time
New Events/s
Process Instances
Events Being Processed
Throughput
Extra Capacity
1
1,000,000
20
1,000,000
0
1,000,000
2
1,000,000
20
2,000,000
1,000,000
0
3
1,000,000
20
2,000,000
1,000,000
0
4
1,000,000
20
2,000,000
1,000,000
0
5
1,000,000
20
2,000,000
1,000,000
0
6
1,000,000
20
2,000,000
1,000,000
0
7
1,000,000
20
2,000,000
1,000,000
0
8
1,000,000
20
2,000,000
1,000,000
0
Conclusion: Same Throughput
The Throughput of the two systems is the same.
The first system, with 5s of latency, takes longer to warm up and needs 2.5x more instances, but it still produces the same throughput. 3 seconds later..
What Happens If You Add Scaling?
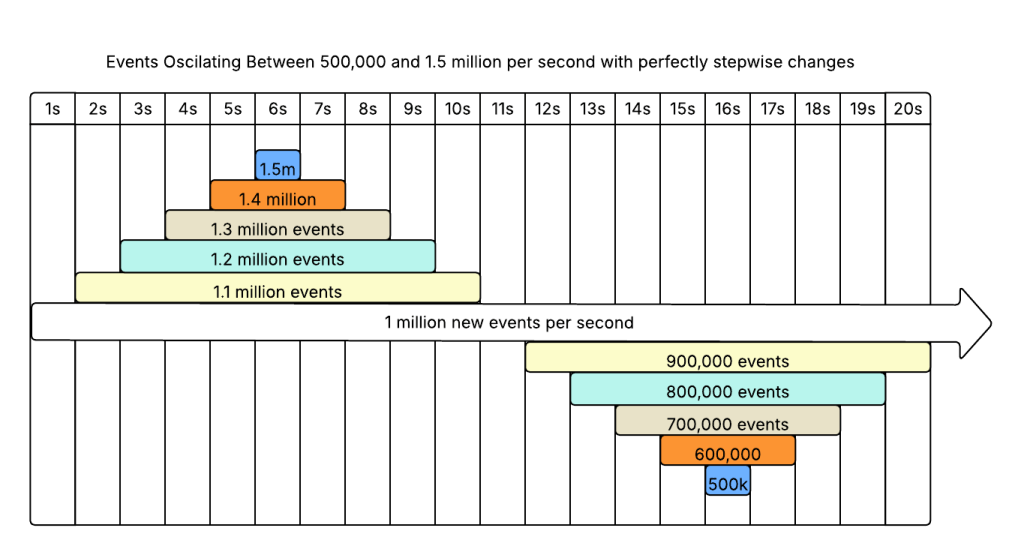
Maybe that model is too simple. Let’s deflate the cow a little bit, vary the input and add auto-scaling.
Let’s make it an average of 1 million messages a second, with peaks and valleys between 500,000 and 1.5 million per second. 20 second period, so it changes +/- 100,000 messages every second. But, we’re only deflating the cow a little bit, so the changes will be step changes at the end of the second.
We will leave our processors completely spherical - they each process 100,000 events simultaneously. It takes 1 second to start a processor, and 1 second to shut down. The only difference between the two is that one takes 2s to process a message and the other takes 5s.
Now our input looks like this:
5s Latency
Time
New Events/s
Process Instances
Events Being Processed
Events Waiting to be Processed
Throughput
Extra Capacity
1
1,000,000
0
0
1,000,000
0
0
2
1,100,000
10
1,000,000
1,100,000
0
0
3
1,200,000
21
2,100,000
1,200,000
0
0
4
1,300,000
33
3,300,000
1,300,000
0
0
5
1,400,000
46
4,600,000
1,400,000
0
0
6
1,500,000
60
6,000,000
1,500,000
1,000,000
0
7
1,400,000
65
6,500,000
300,000
1,100,000
0
8
1,300,000
68
6,800,000
200,000
1,200,000
0
9
1,200,000
70
7,000,000
0
1,300,000
0
10
1,100,000
70
6,900,000
0
1,400,000
1
11
1,000,000
69
6,500,000
0
1,500,000
4
12
900,000
65
5,900,000
0
1,400,000
6
13
800,000
59
5,300,000
0
1,300,000
6
14
700,000
53
4,700,000
0
1,200,000
6
15
600,000
47
4,100,000
0
1,100,000
6
16
500,000
41
3,500,000
0
1,000,000
6
17
600,000
35
3,100,000
0
900,000
4
18
700,000
31
2,900,000
0
800,000
2
19
800,000
29
2,900,000
0
700,000
0
20
900,000
29
2,900,000
200,000
600,000
0
21
1,000,000
31
3,100,000
400,000
500,000
0
2s Latency
Time
New Events/s
Process Instances
Events Being Processed
Events Waiting to be Processed
Throughput
Extra Capacity
1
1,000,000
0
0
1,000,000
0
0
2
1,100,000
10
1,000,000
1,100,000
0
0
3
1,200,000
21
2,100,000
1,200,000
1,000,000
0
4
1,300,000
23
2,300,000
1,300,000
1,100,000
0
5
1,400,000
25
2,500,000
1,400,000
1,200,000
0
6
1,500,000
27
2,700,000
1,500,000
1,300,000
0
7
1,400,000
29
2,900,000
1,400,000
1,400,000
0
8
1,300,000
29
2,900,000
1,300,000
1,500,000
0
9
1,200,000
29
2,700,000
0
1,400,000
2
10
1,100,000
27
2,500,000
0
1,300,000
2
11
1,000,000
25
2,300,000
0
1,200,000
2
12
900,000
23
2,100,000
0
1,100,000
2
13
800,000
21
1,900,000
0
1,000,000
2
14
700,000
19
1,700,000
0
900,000
2
15
600,000
17
1,500,000
0
800,000
2
16
500,000
15
1,300,000
0
700,000
2
17
600,000
13
1,100,000
0
600,000
2
18
700,000
11
1,100,000
100,000
500,000
0
19
800,000
12
1,200,000
300,000
600,000
0
20
900,000
15
1,500,000
300,000
700,000
0
21
1,000,000
18
1,800,000
300,000
800,000
0
Result - Latency Does Not Impact Throughput
Our slightly less spherical model with perfect step changes produced the same fundamental result:
You can’t increase the throughput of a streaming system to be higher than the input.
Latency has a huge impact on the amount of resources required! The first system, with 5s latency, fluctuated between 29 and 70 instances. The second system, with 2s latency, fluctuated between 11 and 29.
The second system’s maximum scale out was equal in size to the first system’s minimum.
And yet, neither system was able to get above 1.5 million events/s.
No matter how non-spherical the cow may be, you can’t sustain a throughput faster than then inputs.
Getting MVPs to actually be Minimum, Viable, and Products is surprisingly complex. In this epsiode, Isaac, Dustin, and I dive into the tradeoffs between simplicity and scalability, the Goldilocks Problem, and overly long development cycles.
If you've ever worked on an MVP that became a full product before it launched, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
A counter intuitive property of streaming systems is that latency has no long term impact on throughput. Increasing or decreasing latency will give a short term change, but once the system stabilizes in its steady state, the throughput will be the same as before.
How can latency and throughput, two important performance metrics, be unrelated?
Let’s define some terms
Latency is the amount of time between when a message is sent and when it is fully processed. This includes the time spent getting the message onto the stream, in queue waiting to process, and process time.
Throughput is the number of completions in a time period. It could be 1 million messages a second, 5 per hour, or anything else. Throughput doesn’t include processing time, that’s part of latency. The million messages/s could have taken 10ms or 10 minutes each to process; so long as 1 million of them finish every second, the throughput is 1 million/s.
Steady State is when the system is fully warmed up and taking on its full load. For a streaming system, this means that it is consuming the full stream, it is producing its maximum output, and the work in progress is being added to as rapidly as it is finished.
Example
Imagine two systems that receive 1 million events per second. The first system takes 5s to process a million messages, the second system takes 2s to process the same messages.
The latency is different, the throughput is the same!
Implications beyond Latency and Throughput
Besides latency and throughput, there are 3 other notable differences between the two systems.
Higher latency means more events in flight. When it gets to steady state, the first system will be working on 5 million events at a time, the second system will only be working on 2 million. This usually means that the first system will require more resources - bigger queues, more workers, a higher degree of parallelism, etc.
Higher latency means slower startup. It takes 5 seconds for events to start emerging from the first system, but only 2 seconds for the second system.
Higher latency means slower shutdown. At the other end of the lifecycle, systems with higher latency take longer to drain and safely shut down than systems with lower latency.
Summary
Why doesn’t latency matter? Because streaming systems have constrained inputs. So long as the system has enough capacity to handle 100% of the inputs, then latency doesn’t impact throughput.
Latency still controls the system requirements; slow is expensive!
Does Conway's Law apply to software quality? In this episode, Isaac, Dustin, and I explore how company culture and structure shape software.
If you've ever wondered about the forces that shape your code base, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
How can you determine the mertis of consolidating or diversifying your tech stack? In this episode we discuss the how consolidation and diversification impact the business, engineering efficiency, and cross-team dynamics.
If you've been wondering how to go about debating your tech stack, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
This week, Isaac and I dive deep into an Allen Holub suggestion that developers should 'rebuild' instead of 'rewrite' software. Are we all saying the same thing? Is there some neuance between rebuilding, rewriting, and refactoring?
If you've been wondering if you should even bother updating your legacy system, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
It is all well and good to say "Never Rewrite", but what do you do if you find yourself part of one? In this episode Isaac and discuss the steps and thinking that will help you stop a rewrite faster and safer than waiting for it fail.
If you're working on a rewrite and don't know what to do, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
Guest Nick Gerace discusses how he backed into a rewrite of the core engine at System Initiatives. Nick walks us through how and why his work to add plugins and package management ended with a new core engine that still lacks package management.
If you want to hear about the philosophy and tradeoffs behind a successful rewrite, this episode is for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!