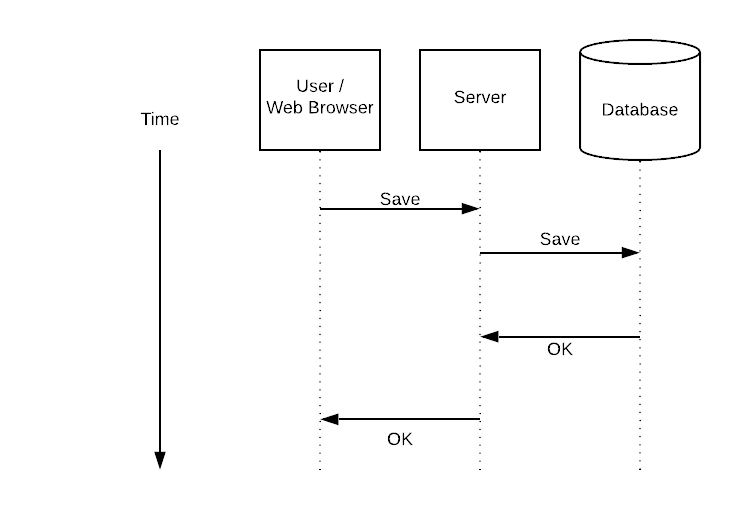
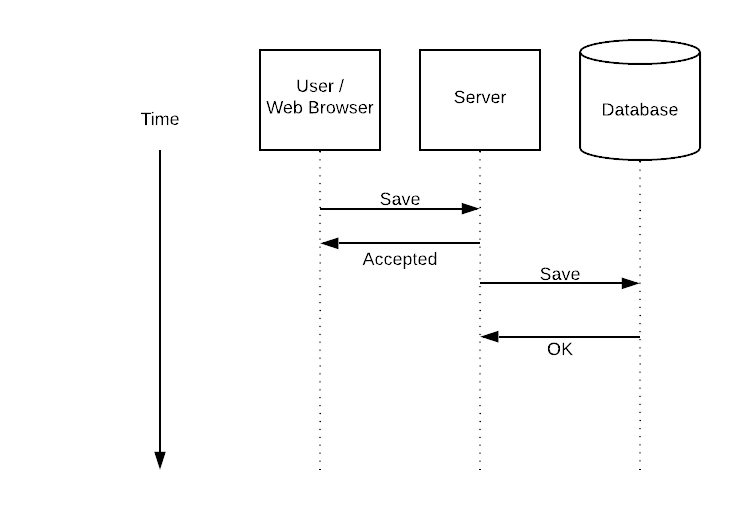
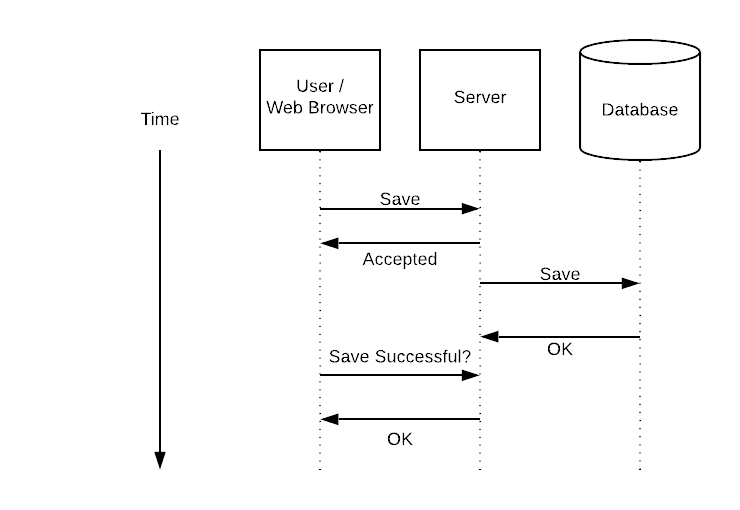
Scaling Bugs don’t really exist, you will never find “unable to scale” in your logs. Scaling bugs are timing, concurrency and reliability bugs that emerge as your system scales. Today I’m going to show you 4 signs that your system is being plagued by scaling bugs, and 4 things you can do to buy time and minimize your client’s pain.
Scaling bugs boil down to “Something that used to be reliable is no longer reliable and your code doesn’t handle the failure gracefully”. This means that they are going to appear in the oldest parts of your codebase, be inconsistent, bursty, and hit your most valuable clients the hardest.
Scaling Bugs appear in older, stable, parts of your codebase
The oldest parts of your are typically the most stable, that’s how they managed to get old. But, the code was also written with lower performance needs and higher reliability expectations.
Reliability bugs can lay dormant for years, emerging where you least expect it. I once spent an entire week finding a bug deep in code that hadn't changed in 10 years. As long as there were no problems, everything was fine, but a database connection hiccup in one specific function would cause a cascading failure on a distributed task being processed on over 30 servers.
Database connectivity is ridiculously stable these days, you can have hundreds of servers and go weeks without an issue. Unless your databases are overloaded, and that’s when the bug struck.
Scaling Bugs Are Inconsistent
Sometimes the system has trouble, sometimes things are fine. Even more perplexing is that they occur regardless of multi-threading or the statefulness of your code.
This makes scaling bugs difficult to find, since you’ll never be able to reproduce them locally. They won’t appear for a single test execution, only when you have hundreds or thousands of events happening simultaneously.
Even if your code is single threaded and stateless, your system is multi-process and has state. A serverless design still has scaling bottlenecks at the persistence layer.
Scaling Bugs Are Bursty
Bursty means that the bugs appear in clusters, usually in ever increasing numbers after ever shorter intervals. Initially the error crops up once every few weeks and does minimal damage, so it gets documented as low priority and never worked on. As your platform scales though, the error starts popping up 5 at a time every few days, then dozens of time once a day. Eventually the low priority, low impact bug becomes an extremely expensive support problem.
Scaling Bugs Hit Your Most Valuable Clients Hardest
Which are the clients with the most contacts in a CRM? Which are the ones with the most emails? The most traffic and activity?
The same ones paying the most for the privilege of pushing your platform to the limit.
The impact of scaling bugs mostly fall on your most valuable clients, which makes their potential impact high in dollar terms.
Four ways to buy time
These tactics aren’t solutions, they are ways to buy time to transform your system to one that operates at scale. I’ll cover some scaling tactics in a future post!
Throw money at the problem
There’s never a better time to throw money at a problem then the early stages of scaling problems! More clients + larger clients = more dollars available.
Increase the number of servers, upgrade the databases, and increase your network throughput. If you have a multi-tenant setup, add shards and decrease the number of customers running on the same hardware.
If throwing money at the problem helps, then you know you have scaling problems. You can also get a rough estimate of the time-for-money runway. If the improved infrastructure doesn’t help you can downgrade everything and stop spending the extra money.
Keep your Error Rate Low
It’s common for the first time you notice a scaling bug to be when it causes a cascading system failure. However, it’s rare for that to be the first time the bug manifested itself. Resolving those low priority rare bugs is key to keeping catastrophic scaling bugs at bay.
I once worked on a system that ran at over 1 million events per second (100 billion/day). We had a saying: The nice thing about this system is that something that’s 1 in a million happens 60 times a minute. The only known error we let stand: Servers would always fail to process the first event after a restart.
Retries
As load and scale increases, transient errors become more common. Take a design cue from RESTful systems and add retry logic. Most modern databases support upsert operations, which go a long way towards making it safe to retry inserts.
Asynchronous Processing
Most actions don’t need to be processed synchronously. Switching to asynchronous processing makes many scaling bugs disappear for a while because the apparent processing greatly improves. You still have to do the processing work, and the overall latency of your system may increase. Slowly and reliably processing everything successfully is greatly preferable to praying that everything processes quickly.
Congratulations! You Have Scaling Problems!
Scaling bugs only hit systems that gets used. Take solace in the fact that you have something people want to use.
The techniques in this article will help you buy enough time to work up a plan to scale your system. Analyze your scaling pain points to gain insight into which parts of your system are most useful to your clients and prioritize your refactoring accordingly.
Remember that there are always ways to scale your current system without resorting to a total rewrite!