I’ve been explaining what queues are, and why using a database as a queue is a bad idea, today I’m going to expand your toolkit, explain how Topics create alternatives to rewrites, and give a concrete example.
Topics allow multiple queues to register for incoming messages. That means instead of publishing a message onto a queue, you publish onto zero or more queues at once, and there is no impact on the publisher. One consumer, no consumer, 100 consumers, you publish one message onto a topic.
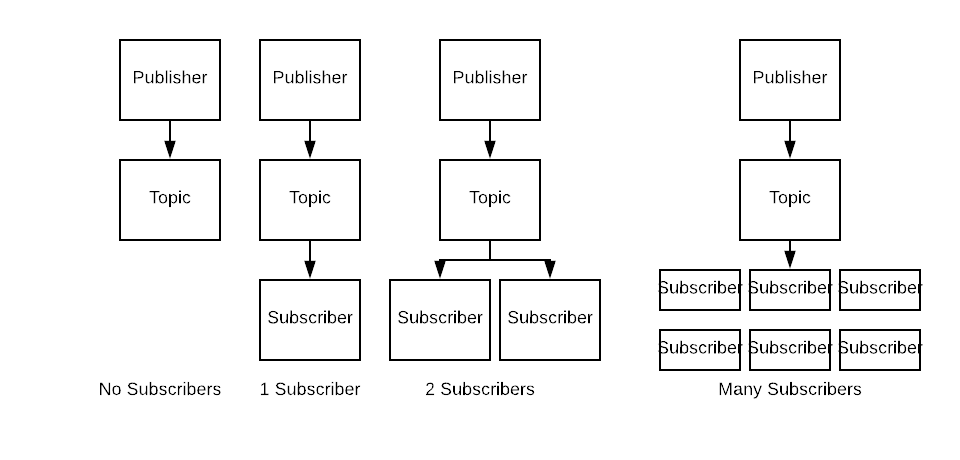
All of these situations require the same effort and resources from your publisher.
For a SaaS company with services running off queues, Topics give your developers the ability to create new services that run side-by-side with your existing infrastructure. New functionality off of your existing infrastructure, without doing a rewrite! How does that work?
Adding a new consumer means adding another Queue to the Topic.
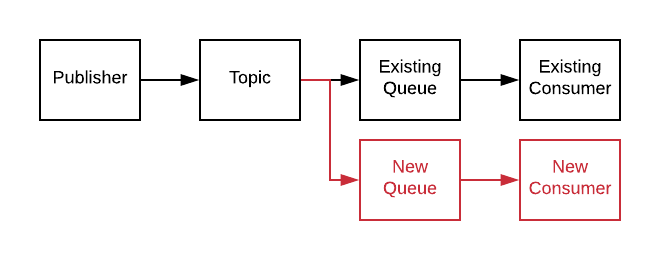
No code changes for any existing services. This is extremely valuable when the existing services are poorly documented and difficult to test.
You can test new versions of your code through end-to-end tests.
Since you can now create two sets of the data, you can run the new version in parallel with the current version and compare the results. Rinse, repeat until you feel confident in sending your customers results from the new system.
It’s not ideal, but you’ll sleep a whole lot easier at night knowing that the original code and original output remains untouched.
New uses for your message flow have no impact on your existing services.
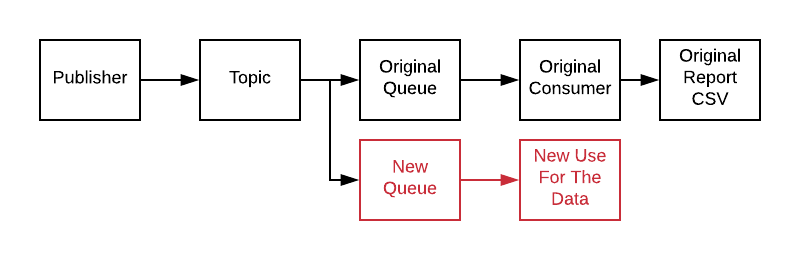
Consuming data becomes “loosely coupled”. Freed from potentially impacting the existing, difficult, code, new reports, monitoring and other ideas become feasible and exciting instead of dread inducing. New uses don’t even have to be in the same programming language!
A concrete example; How Topics can be used to create monitoring on a legacy system:
I worked for a company that was processing jobs off of a queue. This was an older system that had evolved over a decade and was a mess of spaghetti code. It mostly worked, but was not designed for any kind of observability. Because jobs like hourly reports would run, rerun, and even retry, knowing whether a specific hourly report completed successfully was a major support headache.

When challenged to improve the situation the lead developer would shrug and say that nothing could be done with the current code. Instead, he had a plan to do a full rewrite of the scheduler system with logging, tests, and observability baked in. The rewrite would take 6 months. The flaws, bugs and angry customers weren’t quite enough to justify a developer spending 6 months developing a new system. Especially since the new system wouldn’t add value until it was complete. The company didn’t have the resources for a rewrite, but it did have me.
The original system was using SQS on AWS as the queue. We changed the scheduler code to use AWS’s Topic service, SNS, instead. We had SNS write incoming messages to the original SQS queue, and called it a release.
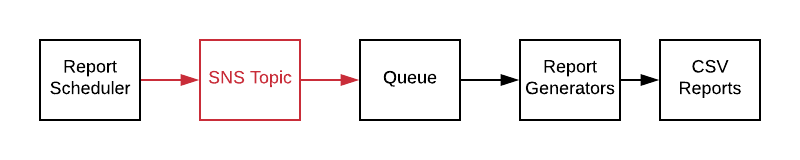
We now had the option and ability to add new services without any further disruption or risk to the original job processor.
We created a new service with the creative name Task Monitor, created a new SQS queue and added it as a listener to SNS. Task Monitor maintained a list of active tasks. It would read messages off a queue and create an entry in an in memory list. Every 5 minutes it would iterate the list and check the status of the task against the database and remove completed tasks.
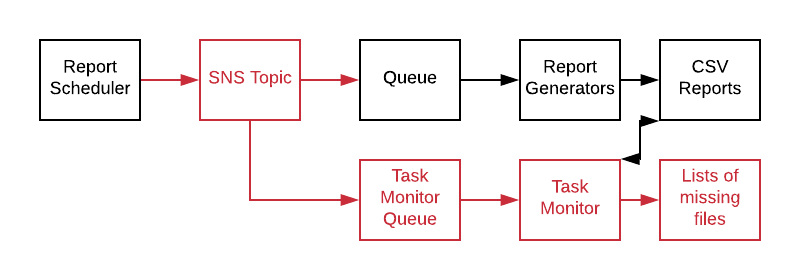
Surviving tasks were added to “Over 5 min” list, “Over 10 min list”, etc and the data was exposed via a simple web api framework. Anything over 45 minutes resulted in an alert being generated.
We now had visibility into which tasks were slipping through the cracks, and with the pattern exposed we were quickly able to fix the bugs. Client complaints ceased (about scheduled reports anyway), which reduced the support load by about 60% of one developer. With almost 3 additional developer days per week we were able to start knocking out some long delayed features and refactoring.
All of these changes were created by a simple change of a call to SQS to a call to SNS. We didn’t need to dive deep into the legacy system to add monitoring and instrumentation.
The additional cost and load of using Topics is negligible, but they create amazingly powerful opportunities, especially for legacy systems that are difficult to refactor.
When your developers say that there’s no way to improve a queue based system without rewriting it, look into Topics. They’re your Best Alternative to a Total Rewrite.
