SaaS Scaling anti-patterns: The database as a queue
Using a database as a queue is a natural and organic part of any growing system. It’s an expedient use of the tools you have on hand. It’s also a subtle mistake that will consume hundreds of thousands of dollars in developer time and countless headaches for the rest of your business. Let’s walk down the easy path into this mess, and how to carve a way out.
No matter what your business does on the backend, your client facing platform will be some kind of web front end, which means you have web servers and a database. As your platform grows, you will have work that needs to be done, but doesn’t make sense in an api / ui format. Daily sales reports and end of day reconciliation, are common examples.

The initial developer probably didn’t realize he was building a queue. The initial version would have been a single table called process which tracked client id, date and completed status. Your report generator would load a list of active client ids, iterate through them, and write done to the database.
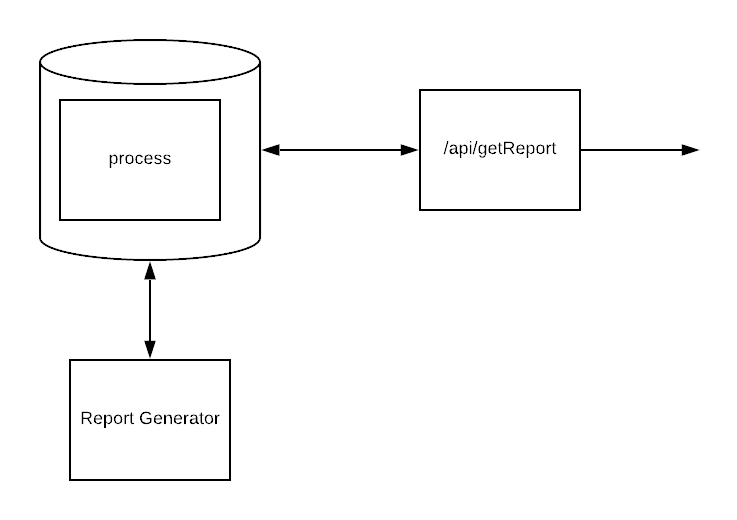
Simple, stateful and it works.
For a while.
But, some of your clients are bigger, and there are a lot of them, and the process was taking longer and longer, until it wasn’t finishing overnight. So to gain concurrency and added worker processes your developers added “Not started” and “in process” states. Thanks to database concurrency guarantees and atomic updates, it only took a few releases to get everything working smoothly with the end-to-end processing time dropping back to something manageable.
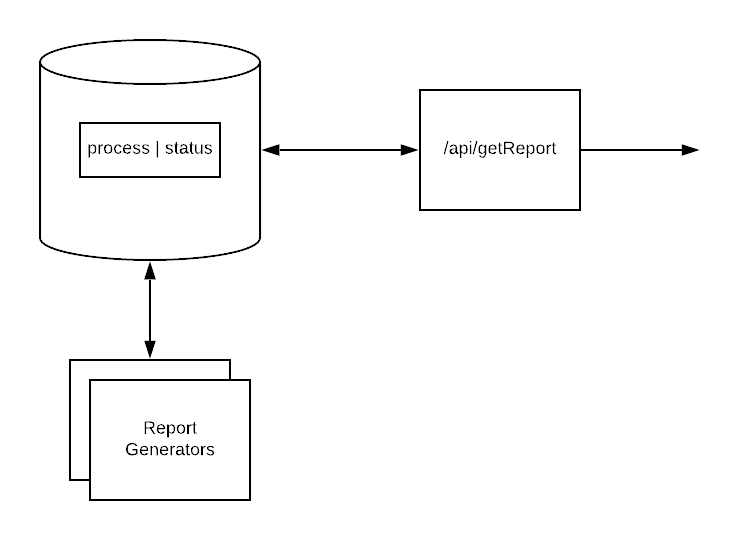
Now the database is a queue and preventing duplicate work.
There’s a list of work, a bunch of workers, and with only a few more days of developer time you can even monitor progress as they chew through the queue.
Except your devs haven’t implemented retry logic because failures are rare. If the process dies and doesn’t generate a report, then someone, usually support fielding an angry customer call, will notice and ask your developers to stop what they’re doing and restart the process. No problem, adding code to move “in-process” back to “not started” after some amount of time is only a sprint worth of work.
Except, sometimes, for some reason, some tasks always fail. So your developers add a counter for retries, and after 5 or so, they set the state to “skip” so that the bad jobs don’t keep sucking up system resources.
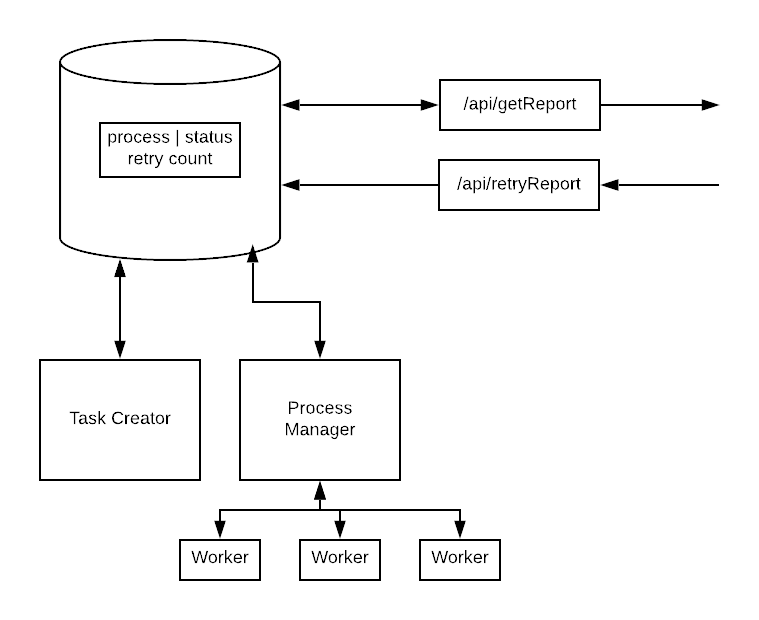
Congratulations! For about $100,000 in precious developer time, your SaaS product has a buggy, inefficient, poor scaling implementation of database-as-a-queue. Probably best not to even try to quantify the opportunity costs.
Solutions like SQS and RabbitMQ are available, effectively free, and take an afternoon to set up.
Instead of worrying about how you got here, a better question is how do you stop throwing good developer resources away and migrate?
Every instance is different, but I find it is easiest to work backwards.
You already have worker code to generate reports. Have your developers extend the code to accept a job from a queue like SQS in addition to the DB. In the first iteration, the developers can manually add failed jobs to the queue. Likely you already have a manual retries process; migrate that to use the queue.
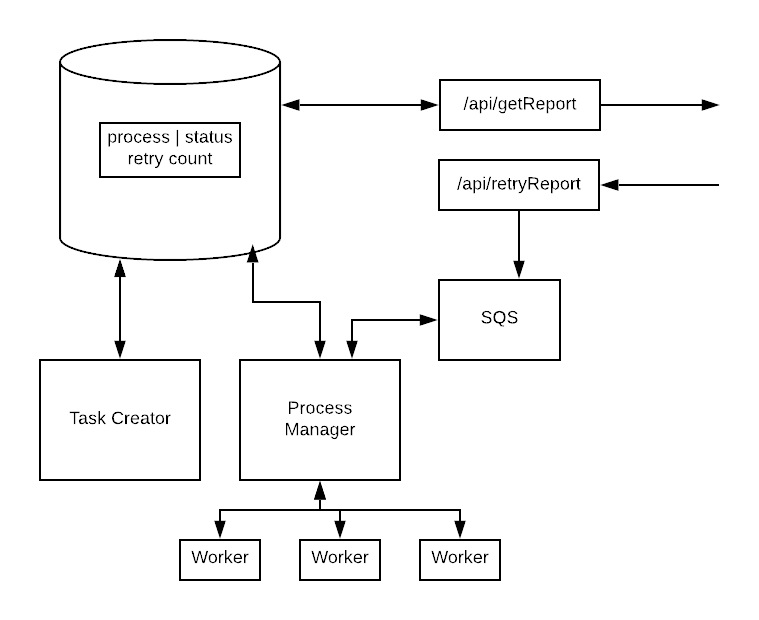
Once you have the code working smoothly with a queue, you can start having the job generator write to the queue instead of the database. Something magically usually happens at this point. You’ll be amazed at how many new types of jobs your developers will want to implement once new functionality no longer requires a database migration.
Soon, you’ll be able to run your system off the db or a queue, but the db tables will be empty.
Only then do you refactor the db queues out of your codebase.
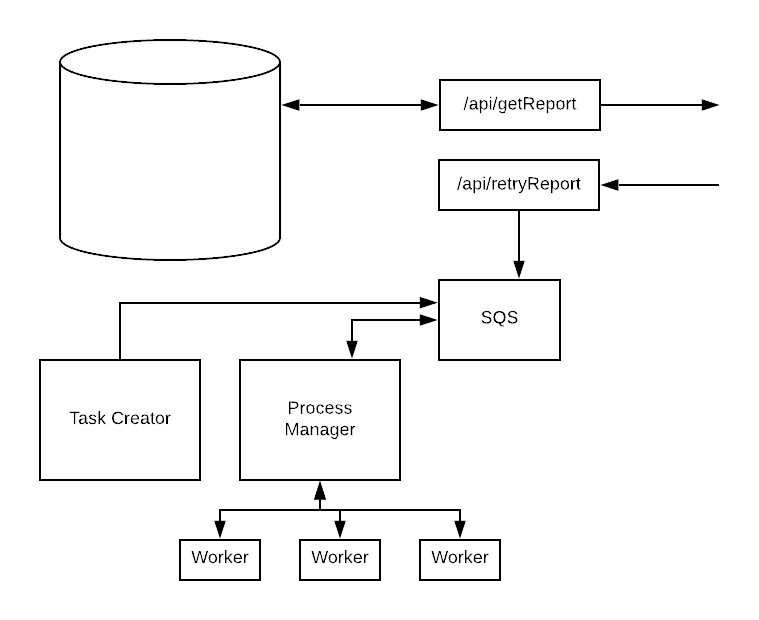
Adding a proper queue system gets your team out of the hole and scratches your developers itch for shiny and new technology. You get improved functionality after the very first sprint, and aren’t rewriting your code from scratch.
That’s your best alternative to a total rewrite, start today!