The SaaS Business Model can be confusing to anyone not intimately familiar with how it works. For developers, this makes it hard to understand priorities, see the levers, and understand their impact. This post is going to try a simple metaphor.
The SaaS Business Model is like pumping air into a balloon with a leak.
The pump represents new customers, the leaks are churn, and customers are the air in the balloon - the life breath of the SaaS.
You want to pump as hard as possible to get as many customers as possible. But the more customers you acquire, the more the balloon fills, the more pressure there will be pushing against the leaks.
SaaS Always Needs New Customers
A SaaS company can never stop acquiring new customers, because it can never stop losing customers. Through no fault of their own, the SaaS customers' needs will change and some will go out of business. Without a steady stream of new customers, the balloon will deflate and the SaaS will go out of business
The Pump And The Leaks Are Tradeoffs
The Pump is the force that brings in new customers. There are many ways to acquire new customers - marketing, sales, and referrals are some of the major ones.
The Leaks are the things that cause customers to churn. Some are outside of your control; customers go out of business. Most are things you can control like price, easy of use, and buggyness.
The pump has a huge impact on the leaks. A SaaS that brings in customers via Enterprise Sales is much more immune to issues with performance, ease of use, and bugs than a SaaS that brings in new customers through referrals.
Features And Quality Can Be Tradeoffs
A common confounding example is when a SaaS brings in new customers through a steady stream of new features. This sets up a model where Features and Feature Quality have become tradeoffs. For developers, this manifests as strange and confounding choices - create lots of features very quickly, and then occasionally go back and fix bugs.
Features bring in new customers, they optimize the pump. Quality reduces churn, it helps patch the leaks. Depending on the pressure in the balloon it may make sense to pump harder, or it may make sense to slow the leaks. Churn is a laggy indicator, problems take a while to drive customers away, and fixing the problem doesn’t immediately reduce churn. Developers also aren’t usually privy to the data so the switch from features to quality can appear with little warning.
Referrals Make Quality Additive
Alternatively, when the pump is driven by referrals, that can drive developers to prioritize Quality and make Price the tradeoff. Software can be made easier, faster, prettier, and more reliable by throwing money at the problem. Referrals come from happy and satisfied customers, great service at a great price.
Conclusion - The SaaS Model Requires Tradeoffs
The SaaS Business Model can be confusing because the drivers can be obscure. Business tradeoffs aren’t static, they change based on the source of new customers and sources of churn. This can be especially confusing for developers because churn is a lagging indicator and the switch from working on acquiring new customers to reducing churn can be sudden.
Above all else, churn is inevitable and you must always be working to acquire new customers!
Scaling bottlenecks choke SaaS growth. Bottlenecks can prevent you from onboarding customers fast enough, make supporting your largest customers impossible, and even leave you saying no to giant deals. Scaling issues impact your annual recurring revenue (ARR), net dollar retention (NDR), and customer lifetime value (CLTV). Imagine telling paying customers that they’ve grown too big and need to move to another platform! It is not only extremely frustrating, it weighs down all of your major metrics.
The rate at which you can onboard new customers is knowable. So is the maximum customer size that has delightful experiences. Customers don’t get too big overnight, they grow with you for years. You can write tools to discover the system maximums. Knowing the limits won’t prevent you from hitting them, but it will prevent you from being surprised.
Scaling bottlenecks are a form of tech debt; bottlenecks are the result of your past decisions, regardless of whether those decisions were intentional. Accidentally creeping up on the system’s limits requires not knowing where they are in the first place.
Do you know where the limits are? Was it not worth investigating because it wasn’t maxed out?
If you don’t know, you will end up turning away customers and limiting ARR growth. Capping customer size also caps CLTV. Saying goodbye to long term customers tanks your NDR and hurts your ARR.
All systems have bottlenecks. The only question is: How do you want to find them? You can seek them out, or you can find them in your bottom line.
I was making a diplomatic comment about some software I was refactoring, “Regardless of the original programmer’s vision, the original code doesn’t work with the final state.” I realized that my version of the code won’t be the final state either. When you work in SaaS, code doesn’t have a final state.
SaaS code has history; it was written to solve a problem. It may have evolved to solve the problem better, it may have evolved because the problem changed.
SaaS code has a present; it is what it is. It solves a problem for some customers. The code might be amazing, but frustrates customers because the problem has changed. The code could be terrible but delights customers because it perfectly solves a static problem.
The code may have a future. The problem can change, the implementation can change.
What SaaS code doesn’t have is a final state. Until you delete it, you can never look at a piece of code and say that won’t be changed again.
Don’t make the mistake of thinking that once you refactor some code, the code will be in its final state. The Service in SaaS will change over time, your code will change with it.
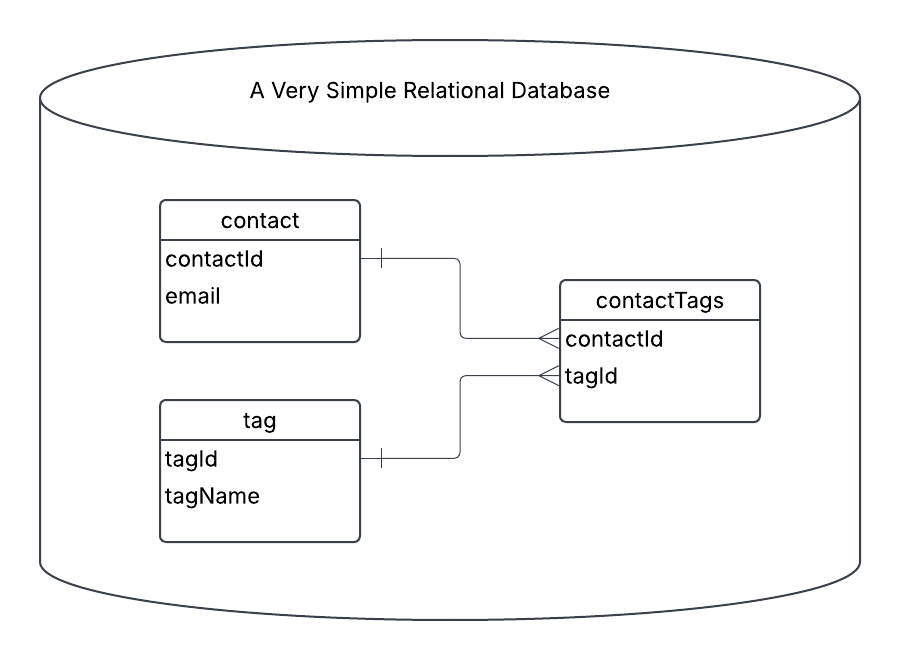
This article walks you through optimizing an import process. I’m going to lay out a simple SaaS db and api, discuss how imports emerge organically, and show you how to optimize for performance.
For the article, we are starting off with a simple CRM that lets you create email contacts, and add tags to them. This is a real, but very small, piece of functionality in all CRMs, and even most SaaS.
API First
Most SaaS start with basic CRUD abilities, an endpoint to create contacts, an endpoint to create tags, and an endpoint to associate tags with contacts. You
[POST] /api/contact - create the contact
[POST] /api/tag - create the tag
[POST[ /api/contact/{id}/tag - create the contactTag relationship
Simple and straightforward. Great for UIs. Cumbersome and clunky if you aren’t a programmer.
CSV Second
Since most people aren’t programmers, and most people can export their data to CSVs, “import data from a CSV” soon emerges.
Here’s our CSV header:
Email, tag1, tag2, …, tagN
Each line starts with an email address, and then 0->N tags that should be associated with the contact. To keep things simple we won’t be deleting any tags that are in the database, but not in the file.
When done well the customer’s file will be written somewhere like Amazon’s S3, and then processed asynchronously. The CSV processing code will be DRY and use the same code from the API.
For each line in the file:
Retrieve the existing contact’s id by email, or create a new contact
For each tag
Retrieve the existing tag’s id by name, or create a new tag
Insert contactId, tagId into the database, if it doesn’t already exist
The code to exercise these steps already exists.
[POST] /api/contact and Retrieve the existing contact’s id by email, or create a new contact run the same code.
[POST] /api/tag and Retrieve the existing tag’s id by name, or create a new tag are the second pair.
[POST[ /api/contact/{id}/tag and Insert contactId, tagId into the database, if it doesn’t already exist complete the functionality.
The emergent model is great because the only new functionality is the ability to store and process the CSV file. The business logic, how data actually gets inserted into the database, gets reused.
Big O, Performance, and Scalability
The algorithm described above has a Big O of O(n^2). For something like an import that’s not great, but it’s also not terrible.
O(n^2) doesn’t tell you much about the real world performance or scalability of the implementation. There are a few different implementations for the data access patterns which could result in wildly different performance characteristics.
In our simple example we look up the tagId in the database for each contact. This mirrors the access pattern for the API. But, we aren’t in the API, we’re in a long running process. We could store the tag-name-to-id information in a map in memory.
Adding an in-memory cache would limit step 2a to running once-per-tag instead of once-per-tag-per-contact. A file with a single tag per contact would save almost ⅓ of its calls. As the number of tags increased, the savings would increase towards ½ of the db calls.
Cutting the number of DB calls in half won’t change the Big O value, but it will greatly improve performance and reduce load on your DB.
Moving From Rows To Columns
The emergent model is great because it reuses code. One drawback is that it involves lots of trips to the database to do single inserts. Trips to the database over a network are relatively slow. Most databases are also optimized for fewer, larger writes.
Processing the CSV file row by row will always push you towards more, smaller, writes because the rows of the file will be relatively short.
Instead, let’s consider a “columnar” approach.
Instead of processing line by line and pushing it to the database, we’re going to sort the data in memory, and push the results to the database.
For simplicity, we will do two passes through the file.
Pass 1 looks very similar to the original process:
Retrieve the existing contact’s id by email, or create a new contact. Store the email/id relationship in a map.
For each tag, retrieve the existing tag’s id by name, or create a new tag. Store the tagName/id relationship in a map.
At the end of Pass 1, we have ensured that all contacts exist, and that all tags exist.
For Pass 2, we replace emails and tags with ids and build a single, large, insert statement like this:
Insert into contactTags (contactId, tagId) values
(1, 1), (1, 2), (1, 3),
(2, 1), (2, 3),
…
Again, simplifying and glossing over the entire subject of upserts, duplicate keys, etc. This post is dense enough as it is.
How Much Faster Is Going A Column At A Time?
In the real world the impact will vary based on the number of rows in the table, contention, complexity, indexes, and a whole host of variables.
Instead let’s look at it by the number of queries each option requires.
Let’s pretend we were inserting a file with 100 new contacts, and each contact had the same 5 tags.
API / Basic Import
We would insert the contact, then insert the tag, then the 5 contactTags.
That is 11 operations per row - 1 contact, 5 tags, 5 contactTags.
Over 100 rows that works out to 100 contact inserts, 5 tag inserts, 495 tag lookups, 500 contactTag inserts.
That’s 1,100 Operations
Import (or API) with tag caching between rows
Adding the in-memory tag cache greatly decreases the number of operations. We no longer need to do the redundant 495 tag lookups.
Now over the course of 100 rows it works out to 100 contact inserts, 5 tag inserts, 500 contactTag inserts.
That’s 605 Operations, at 45% reduction!
Columnar
Finally, we switched to a 2-pass columnar strategy. Instead of doing 500 contactTag inserts, we do a single insert with 500 clauses.
Now our 100 rows become 100 contact inserts, 5 tag inserts, 1 contactTag insert.
That’s 105 Small Operations and 1 Large Operation. That’s a 90% reduction from our initial version, and an 82% reduction from the improved version!
Reminder - that one large operation is going to take significantly longer than any one of the single inserts. You won’t see an 82-90% reduction in processing time. In the real world you would probably cut time by 50%, a mere 2x improvement!
The columnar work could be further optimized to be 1 large insert for contacts, 1 large tag insert, and 1 large contactTag insert. It is more complicated because we need to get the ids, but we could get it down to as little as 5 total db operations - 3 Large Inserts and 2 key lookups. I can cover the final technique in another post if there is interest.
Summary - Tradeoffs Make Columnar Fastest
Having your import process reuse the code from your API is a great way to start. Because of the code reuse the only thing you have to implement is the file handling. That keeps things simple and lets you get the feature out fast.
But, following your API’s code path is also going to be very inefficient and not scale well.
Changing strategies to favor fewer, larger, operations can reduce the number of operations by 80-90% and increase real world performance by 50% or more.
In a SaaS, state exists in many places, some of them outside of your control. If you don’t know where to look, you will never truly understand your system.
State You Can Control
As systems grow in complexity, state creeps into an ever growing number of places:
Databases
Caches
Running Software
Config Files
Shell scripts
Flat files
Do your caches have state? If they went down and it impacted anything other than performance, then they have state.
Do your shell scripts have state? If they reference specific customers then they certainly do.
The list goes on.
Some of your state has backups, like databases, source code, and some config. Your only backups for running software and caches are more instances of running software and caches.
State You Can’t Control
State also creeps into things that aren’t software, and you can’t control:
Tribal knowledge
Manual Procedures
Anything in someone’s head that isn’t documented
People are a critical, and critically overlooked, part of any complex system. The most statefull people aren’t the programmers. It’s the operations and support people that interact with customers that have the most state and least backup.
Disaster Recovery and Cold Start
A cold restart is the hardest kind of disaster recovery. You have all new server instances, whatever is in source control, and whatever is in your backups.
Things that live in people’s heads are even harder to recover. Which repos are important, which services are supposed to run, what does the system even look like?
Depending on your setup you may be ok, you may never recover.
I was at GuaranteedRate when it acquired Discover's Home Loan operations. As part of the acquisition we got their mortgage software and their developers, but no state. I watched the team of developers that created the system spend a year trying to do a cold restart. They failed.
Consider State Now, Before It Gets Away From You
State grows organically with systems and keeping it under control requires effort. Beyond the fear of disaster recovery, knowing where state exists in your system is key to maintenance and growth over time.
Once you start looking for state in your systems, you’ll find it everywhere.
20 Things You Shouldn’t Build At A Midsize SaaS was about technical problems developers at a midsize SaaS shouldn’t try to solve. Is midsize SaaS development all glue work? Have all the problems been solved?
Of course not. Midsize SaaS is the garden of Refactoring, Scaling, and Performance.
To make it sound fancy: The deep work for developers at a midsize SaaS is designing solutions for emergent architectural problems.
A Midsize SaaS Has Different Problems Than A Startup SaaS
Startups have unproven theories about what customers want. They need to get features out as quickly as possible to test theory against reality. Worrying about multiple data centers, global latency, or the performance of features customers can’t see, is a waste of time.
At a startup you should write good code, find product market fit, and don’t worry about how the system will perform when you have 10,000 paying customers.
Once you have thousands of paying customers, that’s when architectural gardening kicks in.
How To Support What Customers Want
The startup phase will leave you with a valuable product and an almost random set of assumptions. You get to puzzle out the assumption, the reality, and choose solutions.
If your systems are in the United States, and all of your customers are in the United States, you will have different architecture needs than if your customers are globally distributed. Linear and exponential scaling produce different problems and require different solutions.
You need to identify which problems you have, and iterate towards standard solutions. Standard solutions are critical because it makes your competitive advantage, the differences that are valuable, shine through. You can’t find the valuable unique differences when everything in your system is bespoke.
Conclusion
The deep work at a midsize SaaS is identifying emerging problems and iterating towards solved solutions. Pathfinding from wherever the startup phase has left you towards known destinations. Moving towards known standard solutions makes it easier to find and improve valuable differentiators. Building unique versions of everything makes everything harder without adding value to your customers.
First, don’t panic. We’ve all been there. I have built some of these things myself - multiple CSV writers and parsers, a DateTime library, and an ORM. We are all human, and we all make mistakes from time to time.
Whether you built, or are responsible for, a bad implementation of other software, what do you do now? It depends on which of 3 buckets the implementation falls into.
It works and you don’t need to touch it
CSV parsers and writers get written a lot because they are very simple. Yes there are edge cases when it comes to escaping strings and unicode, but mostly once you have it working, it’s “fine”.
If you don’t need to touch it, don’t! Let sleeping dogs lie. Ideally put a comment in the code that the next dev should replace it with a standard library instead of expanding the code.
It works ok, but it’s incomplete
This is the biggest bucket. Implementations of DSLs, ORMs, and Frameworks usually fall into this group - the software works ok, but it is missing key features and robustness. Observability is usually extremely lacking.
This makes the software low priority tech debt. There’s opportunity cost from continuing to use it, a cost to replacing it, but no direct development costs.
Generally speaking, this is the kind of thing that gets ignored until you need a missing key feature. Then the debate between continuing with the local implementation and replacing it, resumes.
The best way to approach these situations is to look at the interfaces and requirements for the replacement software, and converge the local implementation over time. This combines regular maintenance with replacement work. As a bonus, it lowers the cognitive load on developers by making the local implementation work more like standard offerings.
It requires continuous maintenance
Some kinds of software require continuous maintenance. When you write your own, you have to do all the maintenance yourself.
Scripting languages are a wonderful source of Halting Problem issues. Your customers will be excellent at creating scripts that will never exit and will consume resources until the server restarts. The more successful you are, the worse the problem will become.
I saw a SaaS with 2 full time developers working to close all of the ways that customers were accidentally creating infinite loops with their homegrown scripting language.
I worked at a company using objective-c which had extended Apple’s compiler. This was back in the days of installed, on-prem, software. Every time Apple had a release, we had to warn customers not to upgrade until we could re-extend the compiler, recompile, and ship the code.
When you encounter implementations that require continuous maintenance, you have to start working to remove them immediately. The longer they remain, the more entrenched they become. The sunk cost fallacy will work against you in strange and insidious ways.
Iterative removal is the only real option in these cases.
No matter which bucket the badly implemented software falls into, the first step is always to recognize the problem. If there’s already an implementation, you shouldn’t write your own without a good reason.
I have seen developers build a lot of unnecessary and counterproductive pieces of software over the years. Generally, developers at small to midsize SaaS companies shouldn’t build any software that doesn’t directly help them deliver a service to their customers.
Whether it was the zero interest rate period, bad management, or hubris, developers spent a lot of company money on projects that never made sense given their employer’s goals and size. I have seen custom implementations of every type of software on this list. None of it worked better than open source, and none offered a competitive advantage.
If you find yourself developing or managing any of these twenty types of projects, stop and seriously consider what you are doing.
Scripting languages
Compiler extensions
Transpilers
Database extensions
Databases
DSLs
ORMs
Queues
Background work schedulers
GraphQL
Stateful REST
Frontend Frameworks
Backend Frameworks
Servers
Dependency Injectors
CSV writers or parsers
Cryptography Implementations
Logging Libraries
DateTime libraries
Anything from “First principles”
There are always exceptions, if building this software has some competitive advantage, go ahead. In general, anyone suggesting these projects is biting off more than they can chew and doesn’t fully understand the problem they are trying to solve.
Most often things start out as a quick hack - “I’ll just concatenate these strings with a comma, it will be faster than finding a full CSV library.” Soon you’re implementing custom separators and string escaping.
If your company has done their own implementations don’t despair, iterate towards a better library!
Robert Moses used lies and trickery to ensure that his projects were completed. He loved to start projects and let pride, politics, and sunk costs pull them to completion. Software development is notorious for grinding on and delivering projects years late that don’t solve the original problem.
SaaS project deadlines are artificial, usually the only thing that can stop a project is completion. Even projects with no developers will shamble on, zombie-like, eating a bit of everyone’s brain as they stumble through the code.
When you find yourself confronted with a long lived, poorly defined project, start asking questions:
Was there a time element to the project, and has it passed?
Have the assumptions behind the project changed?
Have the company’s goals changed?
Was there a time element to the project, and has it passed?
Calendars are cyclical; it’s technically never too late or too early to get ready for your industry’s high volume period. But if you see a project to scale for Black Friday, in January, there’s a good chance that you don’t need to finish it.
Your company got through Black Friday without the project, why do you need it now?
Have the assumptions behind the project changed?
I have been involved with many “if we switch from technology X to Y, we can save a lot of money” type projects. Less than half produced significant cost savings. In most of the cases we knew that the savings wouldn’t materialize early in the project. The projects kept going anyway.
It is much easier to rationalize “the cost savings may not be there, but technology Y is better” than to work out if the new tech justifies the project on technical merits.
Have the company’s goals changed?
Long running, nebulous, projects run the risk of having the company’s goals change. I “increase performance” and “scale the system”. But when the customer profile changes, I am often scaling the wrong part of the system.
Learning To Question Is The First Step
Before you can stop a project, you have to question the project. Question the timing, the assumptions, and the company’s goals.
If the answers are no, it might be time to stop development.