A while ago I wrote an article, Your Database is not a Queue, where I talked about this common SaaS scaling anti-pattern. At the time I said:
Using a database as a queue is a natural and organic part of any growing system. It’s an expedient use of the tools you have on hand. It’s also a subtle mistake that will consume hundreds of thousands of dollars in developer time and countless headaches for the rest of your business. Let’s walk down the easy path into this mess, and how to carve a way out.
Today I have a live example of a SaaS company, layerci.com, proudly embracing the anti-pattern. In this article I will compare my descriptions with theirs, and point out expensive and time consuming problems they will face down the road.
None of this is to hate on layerci.com. An expedient solution that gets your product to market is worth infinitely more than a philosophically correct solution that delays giving value to your clients. My goal is to understand how SaaS companies get themselves into this situation, and offer paths our of the hole.
What's the same
In my article I described a system evolving out of reporting, layerci's problem:
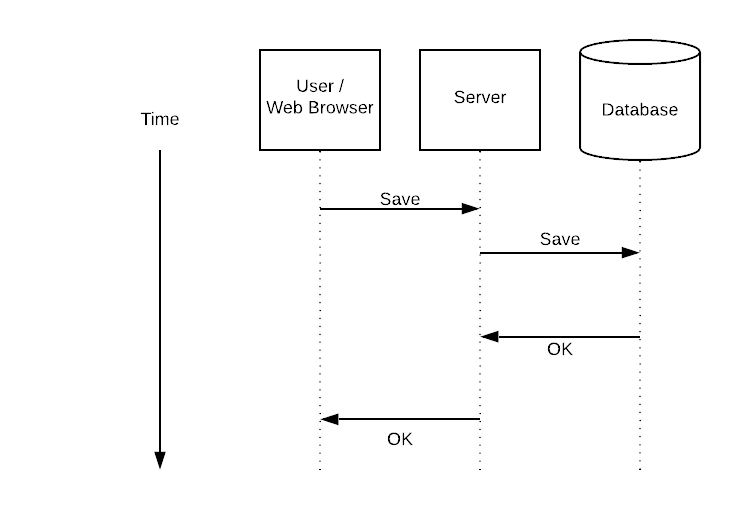
We hit it quickly at LayerCI - we needed to keep the viewers of a test run's page and the github API notified about a run as it progressed.
I described an accidental queue, while layerci is building one explicitly:
CREATE TYPE ci_job_status AS ENUM ('new', 'initializing', 'initialized', 'running', 'success', 'error');
CREATE TABLE ci_jobs(
id SERIAL,
repository varchar(256),
status ci_job_status,
status_change_time timestamp
);
/*on API call*/
INSERT INTO ci_job_status(repository, status, status_change_time) VALUES ('https://github.com/colinchartier/layerci-color-test', 'new', NOW());
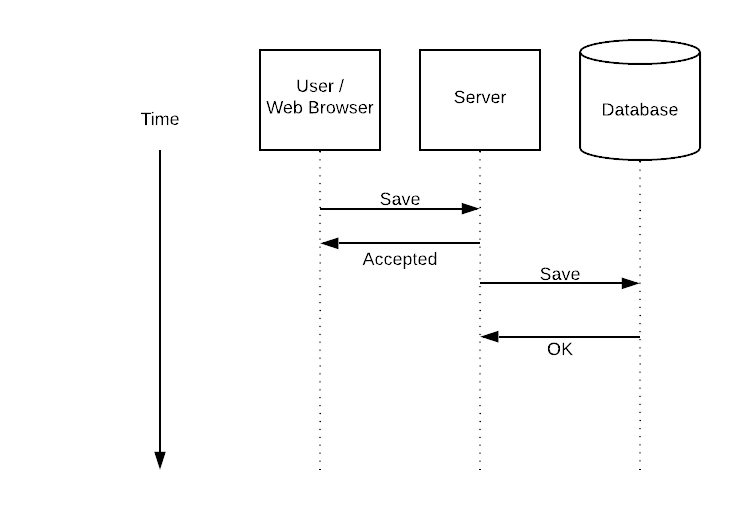
I suggested that after you have an explicit, atomic, queue your next scaling problem is with failures. Layerci punts on this point:
As a database, Postgres has very good persistence guarantees - It's easy to query "dead" jobs with, e.g., SELECT * FROM ci_jobs WHERE status='initializing' AND NOW() - status_change_time > '1 hour'::interval to handle workers crashing or hanging.
What's different
There are a couple of differences between the two scenarios. They aren't material towards my point so I'll give them a quick summary:
- My system imagines multiple job types, layerci is sticking to a single process type
- layerci is doing some slick leveraging of PostgreSQL to alleviate the need for a Process Manager. This greatly reduces the amount of work needed to make the system work.
What's the problem?
The main problem with layerci's solution is the amount of developer time spent designing the solution. As a small startup, the time and effort invested in their home grown solution would almost certainly have been better spent developing new features or talking with clients.
It's the failures
From a technical perspective, the biggest problem is lack of failure handling. layerci punts on retries:
As a database, Postgres has very good persistence guarantees - It's easy to query "dead" jobs with, e.g., SELECT * FROM ci_jobs WHERE status='initializing' AND NOW() - status_change_time > '1 hour'::interval to handle workers crashing or hanging.
Handling failures is a lot of work, and something you get for free as part of a queue.
Without retries and poison queue handling, these failures will immediately impact layerci's clients and require manual human intervention. You can add failure support, but that's throwing good developer time after bad. Queues give you great support out of the box.
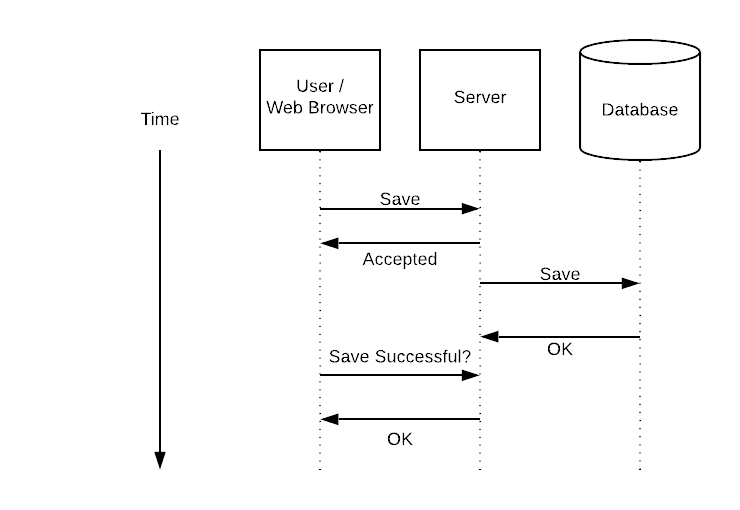
Monitoring should not be an afterthought
In addition to not handling failure, layerci's solution doesn't handle monitoring either:
Since jobs are defined in SQL, it's easy to generate graphql and protobuf representations of them (i.e., to provide APIs that checks the run status.)
This means that initially you'll be running blind on a solution with no retries. This is the "Our customers will tell us when there's a problem" school of monitoring. That's betting your client relationships on perfect software with no hiccups. I don't like those odds.
SCALING Databases is expensive
The design uses a single, ever growing jobs table ci_jobs, which will store a row for every job forever. The article points out postgreSQL's amazing ability to scale, which could keep you ahead of the curve forever. Database scaling is the most expensive piece in any cloud application stack.
Why pay to scale databases to support quick inserts, updates and triggers on a million row table? The database is your permanent record, a queue is ephemeral.
Conclusion
No judgement if you build a queue into your database to get your product to market. layerci has a clever solution, but it is incomplete, and by the time you get it to work at scale in production you will have squandered tons of developer resources to get a system that is more expensive to run than out of the box solutions.
Do you have a queue in your database? Read my original article for suggestions on how to get out of the hole without doing a total rewrite.
Is your situation unique? I'd love to hear more about it!