The Strangler is an extremely effective technique for phasing out legacy systems over time. Instead of spending months getting a new system up to parity with the current system so that clients can use it, you place The Strangler between the original system and the clients.
The Strangler passes any request that the new system can’t handle on to the legacy system. Over time, the new system handles more and more, the legacy system does less and less. Most importantly, your clients won’t have to do any migration work and won’t notice a thing as the legacy system fades away.
A common objection to setting up a Strangler is that it Yet Another Thing that your overloaded team needs to build. Write a request proxy on top of rewriting the original requests! Who has time?
Except, AWS customers already have a fully featured Strangler on their shelf. The Elastic Load Balancer (ELB) is a tool that takes incoming requests and forwards them on to another server.
The only requirement is that your clients access your application through a DNS name.
With an afternoon’s worth of effort you can set up a Strangler for your legacy application.
You no longer need to get the new system up to feature parity for clients to start using it! Instead, new features get routed to the new server, while old ones stay with the legacy system. When you do have time or a business reason to replace an existing feature the release is nothing more than a config change.
Getting a new system up to parity with the legacy system is a long process with little business value. The Strangler lets your new system leverage the legacy system, and you don’t even have to let your clients know about the migration. The Strangler is your Best Alternative to a Total Rewrite!
Pixel Tracking is a common Marketing SaaS activity used to track page loads. Today I am going to try and tie several earlier posts together and show how to evolve a frustrating Pixel Tracking architecture into one that can survive database outages.
This design is governed by database performance. As the load ramps up, users are going to notice lagging page loads. Worse, each event recorded will have to be processed, tripling the database load.
Users are now completely insulated from scale and processing issues.
Dead Database Design
There is no database in the final design because it is no longer relevant to the users’ interactions with your services. The performance is the same whether your database is at 0% or 100% load.
The performance is the same if your database falls over and you have to switch to a hot standby or even restore from a backup.
With a bit of effort your SaaS could have a database fall over on the run up to Black Friday and recover without data loss or clients noticing. If you are using SNS/SQS on AWS the queue defaults are over 100,000 events! It may take a while to chew through the queues, but the data won't disappear.
When your Pixel Tracking is causing your users headaches, going asynchronous is your Best Alternative to a Total Rewrite.
In an earlier post I suggested Asynchronous Processing as a way to buy time to handle scaling bugs. Remembering my friend and his comment “assume I have a hammer, a screwdriver, and a database”, today’s post will explain Synchronous versus Asynchronous processing and discuss how asynchronous processing will help your software scale.
Processing: Synchronous versus Asynchronous
Synchronous Explained
Synchronous processing means that each step starts, does some action, and then starts the next step. Eventually the last action completes and returns, and so on back.
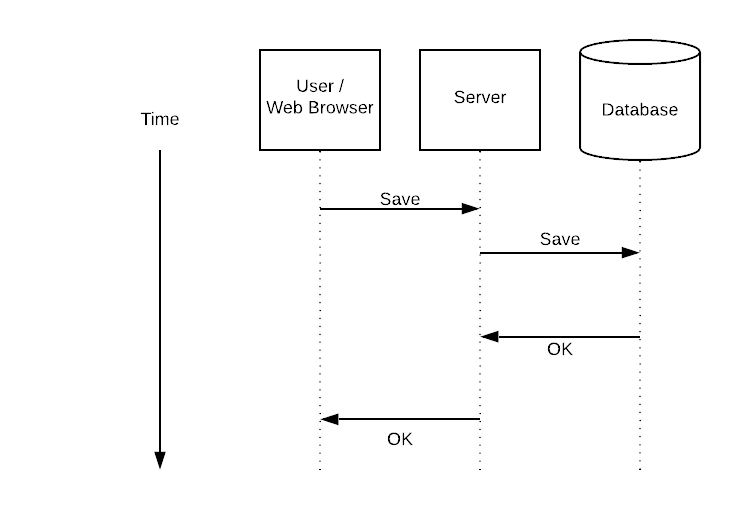
A basic synchronous web request looks like this:
A user clicks save and the browser tells the server to save the data. The server tells the database. The database returns OK, then the server returns OK, and the browser shows a Save Successful message.
Simple to understand, but when you are having scaling problems, sometimes that save time can go from 100ms to 10s. It’s a horrible user experience and unnecessary wait!
Asynchronous Explained
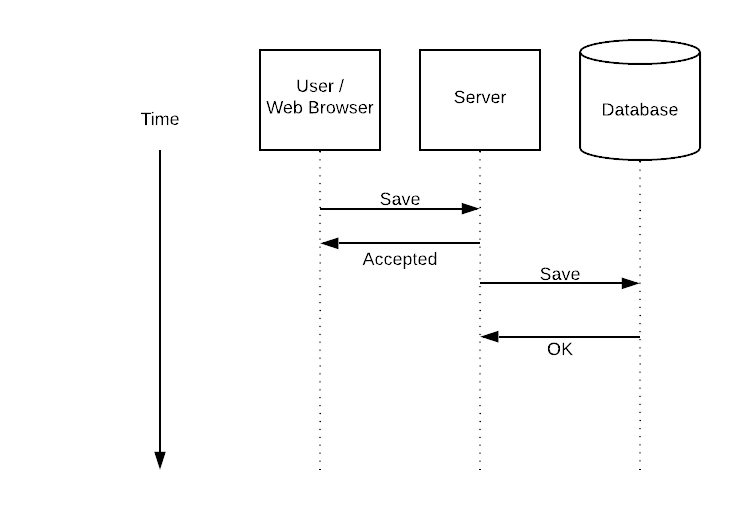
Asynchronous Processing gives a superior user experience by returning to the browser immediately. The actual save will be processed later. This makes things more complex because the request has been decoupled from the processing.
The user is now insulated from scaling issues. It doesn’t matter if the save takes 100ms or 10s, the user gets a consistent experience.
In an asynchronous model, the user doesn’t get notified that the save was successful. For most cases this is fine, the user shouldn’t be worried about whether their actions are succeeding, the client should be able to assume success.
The client being able to assume success does not mean your system can assume success! Your system still needs to handle failures, exceptions and retries! You just don’t need to drag the user into it. Since you no longer have a direct path from request through processing, asynchronous operations can be harder to reason about and debug.
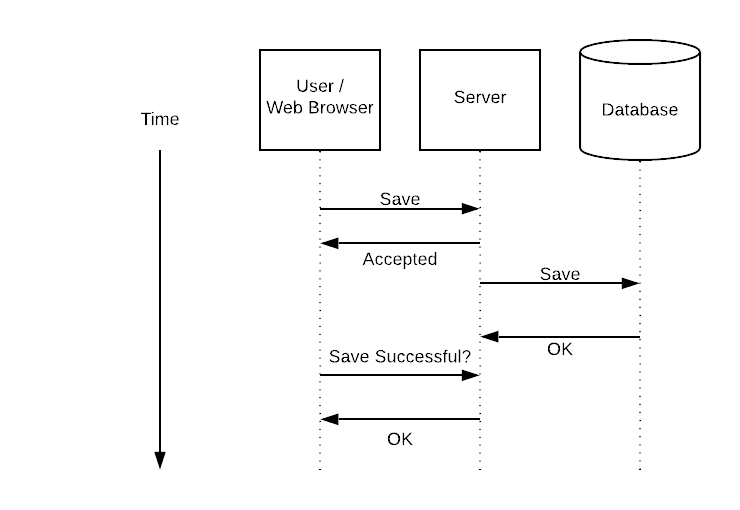
For instances where “blind” asynchronous isn’t acceptable you need a polling mechanism so that the user can check on the status.
How Asynchronous Processing Helps Systems to Scale
With synchronous processing your system must process all of the incoming activity and events as they occur, or your clients will experience random, intermittent, failures.
Synchronous scaling results in numerous business problems:
It runs up infrastructure costs. The only way to protect service level agreements is by greatly over provisioning your system so that there is significant excess capacity.
It creates repetitional problems. Clients can easily impact each other with cyclical behavior. Morning email blasts, hourly advertising spending rates, and Black Friday are some examples.
You never know how much improvement you’ll get out of the next fix. As your system scales you will always be rate-limited by a single bottleneck. If your system is limited to 100 events/s because your database can only handle 100 events/s, doubling the hardware might get you to 200 events/s, or you might discover that your servers can only handle 120 events/s.
You don’t have control over your system’s load. The processing rate is set by your clients instead of your architecture. There is no way to relieve pressure on your system without a failure.
Asynchronous processing gives you options:
You can protect your service level agreements by pushing incoming events onto queues and acknowledging the event instantly. Whether it takes 100ms, 1s, or 10 minutes to complete processing, your system is living up to its service level agreements.
After quickly acknowledging the event, you can control the rate at which the queued events are processed at a client level. This makes it difficult for your large clients to starve out the smalls ones.
Asynchronous architecture forces you to loosely couple your system’s components. Each piece becomes easy to load test in isolation, giving you'll have a pretty good idea about how much a fix will actually help. It also makes small iterations much more effective. Instead of spending 2x to double your databases when your servers can only support another 20%, you can increase spending 20% to match your server’s max capacity. Loosely coupled components can also be worked on by different teams at the same time, making it much easier to scale your system.
You regain control over system load. Instead of everything, all at once, you can set expectations. If clients want faster processing guarantees, you can now not only provide them, but charge accordingly.
Conclusion
Shifting from synchronous to asynchronous processing will require some refactoring of your current system, but it’s one of the most effective ways to overcome scaling problems. You can be highly tactical with your implementation efforts and apply asynchronous techniques at your current bottlenecks to rapidly give your system breathing room.
If your developers are ready to give up on your current system, propose one or two spots to make asynchronous. You will get your clients some relief while rebuilding your team's confidence and ability to iterate. It’s your best alternative to a total rewrite!
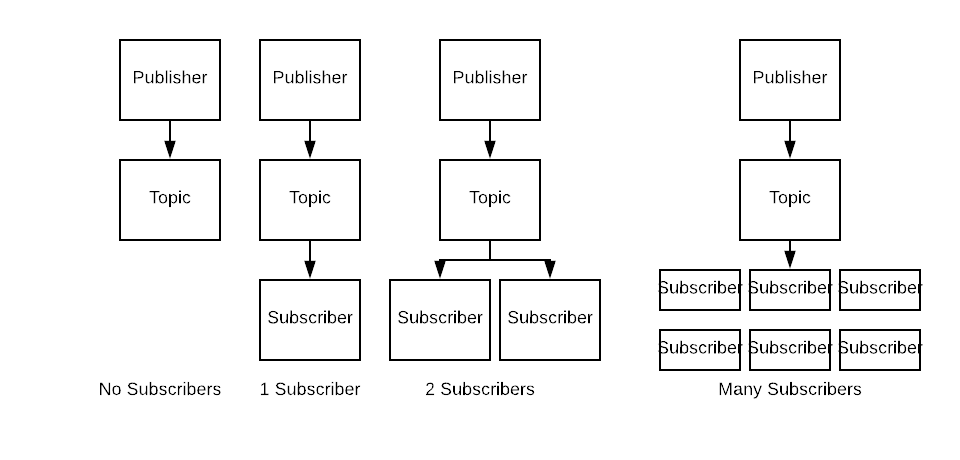
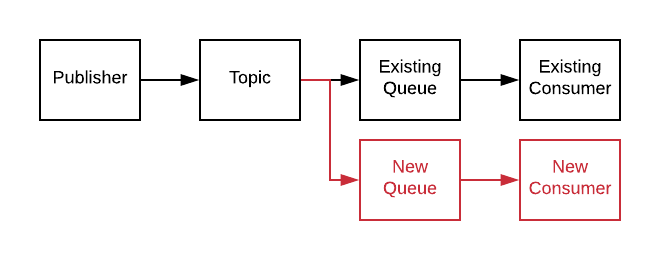
Topics allow multiple queues to register for incoming messages. That means instead of publishing a message onto a queue, you publish onto zero or more queues at once, and there is no impact on the publisher. One consumer, no consumer, 100 consumers, you publish one message onto a topic.
All of these situations require the same effort and resources from your publisher.
For a SaaS company with services running off queues, Topics give your developers the ability to create new services that run side-by-side with your existing infrastructure. New functionality off of your existing infrastructure, without doing a rewrite! How does that work?
Adding a new consumer means adding another Queue to the Topic.
No code changes for any existing services. This is extremely valuable when the existing services are poorly documented and difficult to test.
You can test new versions of your code through end-to-end tests.
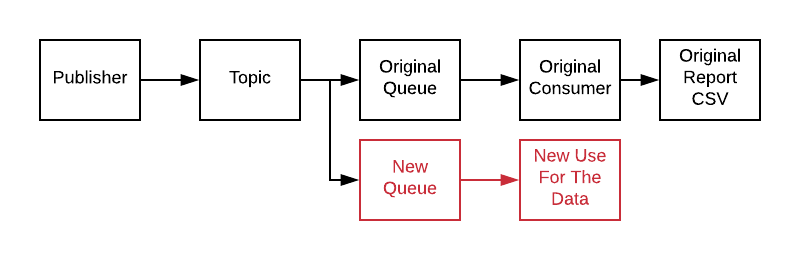
Since you can now create two sets of the data, you can run the new version in parallel with the current version and compare the results. Rinse, repeat until you feel confident in sending your customers results from the new system.
It's not ideal, but you'll sleep a whole lot easier at night knowing that the original code and original output remains untouched.
New uses for your message flow have no impact on your existing services.
Consuming data becomes “loosely coupled”. Freed from potentially impacting the existing, difficult, code, new reports, monitoring and other ideas become feasible and exciting instead of dread inducing. New uses don’t even have to be in the same programming language!
A concrete example; How Topics can be used to create monitoring on a legacy system:
I worked for a company that was processing jobs off of a queue. This was an older system that had evolved over a decade and was a mess of spaghetti code. It mostly worked, but was not designed for any kind of observability. Because jobs like hourly reports would run, rerun, and even retry, knowing whether a specific hourly report completed successfully was a major support headache.
When challenged to improve the situation the lead developer would shrug and say that nothing could be done with the current code. Instead, he had a plan to do a full rewrite of the scheduler system with logging, tests, and observability baked in. The rewrite would take 6 months. The flaws, bugs and angry customers weren’t quite enough to justify a developer spending 6 months developing a new system. Especially since the new system wouldn’t add value until it was complete. The company didn’t have the resources for a rewrite, but it did have me.
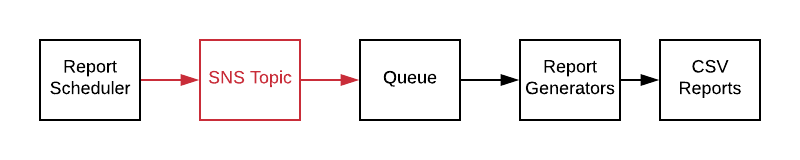
The original system was using SQS on AWS as the queue. We changed the scheduler code to use AWS’s Topic service, SNS, instead. We had SNS write incoming messages to the original SQS queue, and called it a release.
We now had the option and ability to add new services without any further disruption or risk to the original job processor.
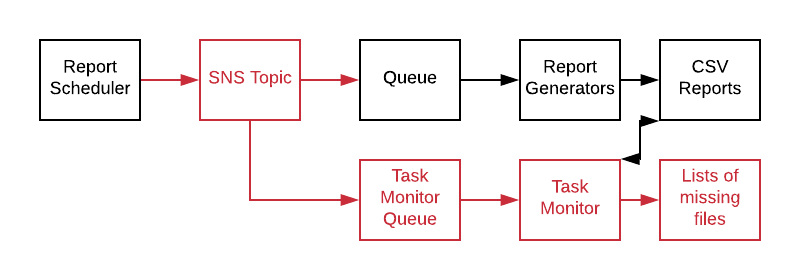
We created a new service with the creative name Task Monitor, created a new SQS queue and added it as a listener to SNS. Task Monitor maintained a list of active tasks. It would read messages off a queue and create an entry in an in memory list. Every 5 minutes it would iterate the list and check the status of the task against the database and remove completed tasks.
Surviving tasks were added to “Over 5 min” list, “Over 10 min list”, etc and the data was exposed via a simple web api framework. Anything over 45 minutes resulted in an alert being generated.
We now had visibility into which tasks were slipping through the cracks, and with the pattern exposed we were quickly able to fix the bugs. Client complaints ceased (about scheduled reports anyway), which reduced the support load by about 60% of one developer. With almost 3 additional developer days per week we were able to start knocking out some long delayed features and refactoring.
All of these changes were created by a simple change of a call to SQS to a call to SNS. We didn’t need to dive deep into the legacy system to add monitoring and instrumentation.
The additional cost and load of using Topics is negligible, but they create amazingly powerful opportunities, especially for legacy systems that are difficult to refactor.
When your developers say that there’s no way to improve a queue based system without rewriting it, look into Topics. They’re your Best Alternative to a Total Rewrite.
Replacement is not a release plan, it’s a sign that you are solving developer’s pain instead of client pain.
Deployment gets glossed over in the pitch: First we will mimic the existing functionality. Then turn off the old system.
Since the plan is to re-implement the current functionality, your developers can start immediately! No need to talk to the clients since they won’t notice any difference until we show them all the wonder improvements!
Developers get super excited about these kinds of rewrites because it is all about them and their pain. The plan fails because the client cares about client pain, not developer pain.
Don’t assume the client wants what are you giving them! Don’t assume they would love for you to give them more features, better code, or anything that excites your developers. A more common situation is that someone has full time job doing manual data extractions, transformations, and other manipulations that software could do in seconds and your developers could write in a week.
Find your client’s pain. Appeal to your developer’s sense of empathy. If they hate dealing with the system, have them imagine the low level person being kept in a pointless job. It’s a good bet that once your developers find out how their software is being used they’ll find that there’s no need for a rewrite; the clients need new tools, not replacements.