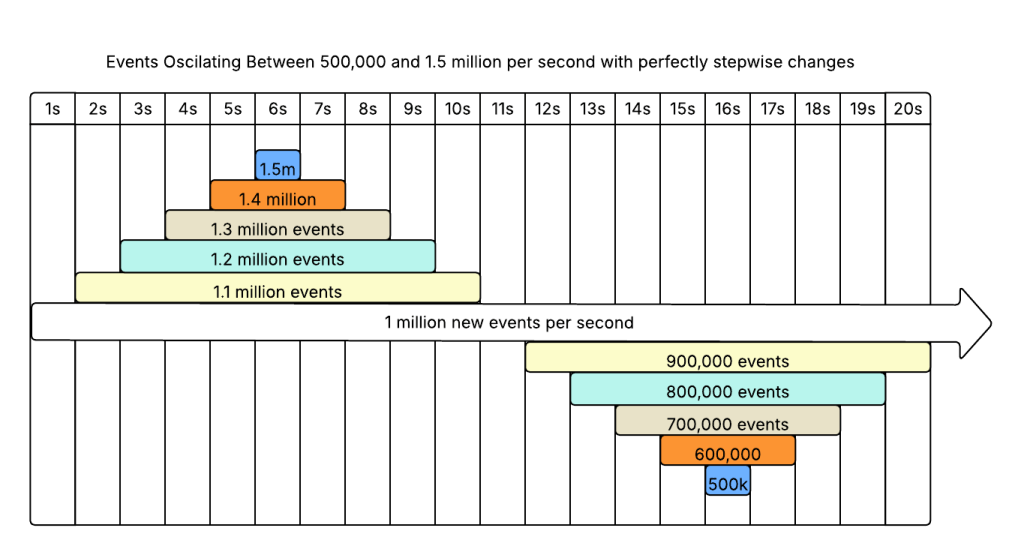
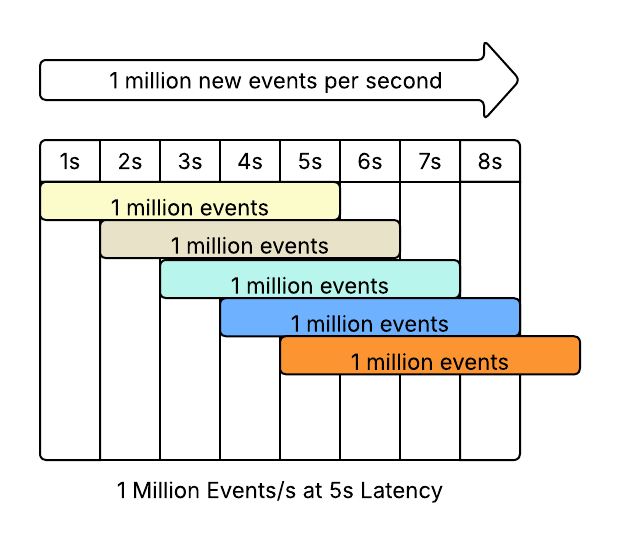
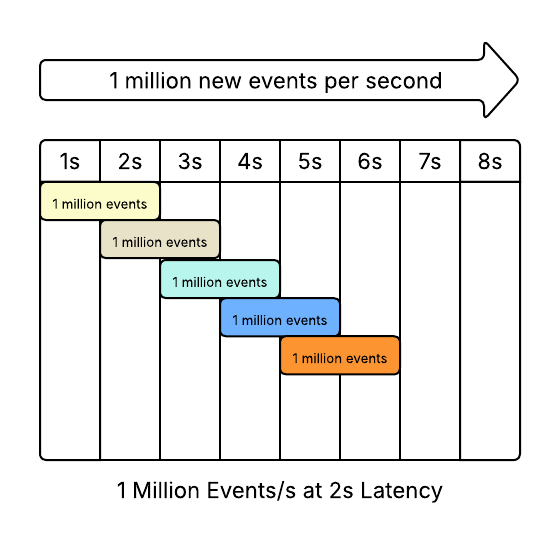
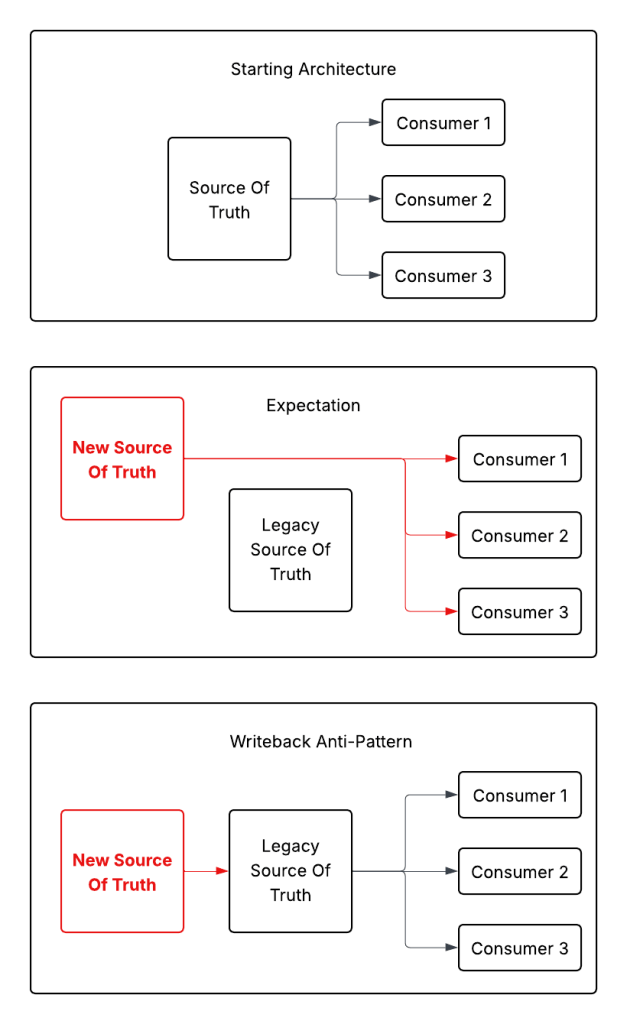
If you come to me saying “we need a rewrite”, I will run you through a lot of “why” questions to discover if you actually need a rewrite. I am basically trying to answer these three questions:
- What will the new system do differently?
- Why can’t you do that in the current system?
- Why can’t you build the new things separately?
Answering these questions yourself will help you think through whether you really need to rewrite your existing system.
Let’s examine each more closely.
What Will The New System Do Differently
What will be different about the new system?
For this exercise you have to ignore code quality, bugs, and developer happiness. Those are all important, but corporate reality hasn’t changed. The same forces that resulted in low quality code, endless bugs, and developer unhappiness are still there. A rewrite might get you temporary relief, but over the long term, the same negative forces will be at work on the new system.
So, what is different about the new system? The differences could be technical, like a new programming language, framework, or architecture. Maybe you need to support a new line of business and the existing system can’t stretch to cover the needs.
Get clear on what will be different, and write it down. These are your New Things.
Why Can’t You Do It In The Current System
Now that you are clear on what New Things you need, why can’t you build the New Things into the existing system?
We are still putting aside issues like the existing code quality, bugs, and developer happiness. If those forces are all that is stopping you from doing the new work in the existing system, I have bad news, those forces will wreck the new system as well. You don’t need new software, you need to change how you write software. Stop now, while you only have one impossible system to maintain.
Other than the forces that cause you to write bad software, why you can’t use the current system. Get clear. Write it down. These are your Forcing Functions.
Why Can’t You Build The New Things Separately?
At this point we know what the New Things are and we know the Forcing Functions that prevent you from extending the current system. Why can’t the New Things live alongside the existing system?
A rewrite requires rewriting all of your existing system. Building New Things in a new system because of Forcing Functions, only requires building the New Things. Why can’t you do that?
By this point office politics are out. Office politics can’t overcome Forcing Functions.
Quality and bugs are also out, because there is no existing code to consider.
Get clear. Write it down. This is your Reasoning.
Now, take your Reasoning, backed by the Forcing Functions, and you have explained how getting the New Things requires a rewrite. If your Reasoning can convince your coworkers, then I’m sorry, you do actually need a rewrite.
If not, it is time to talk about alternatives.
What Happens After I Talk You Out Of A Rewrite
Most rewrites are driven by development culture issues, not the software itself. This brings us back to code quality, bugs, and developer happiness. A rewrite won’t fix any of those issues.
The good news is that you can fix all of them without a rewrite. Even better news is that fixing them will only take about as much effort as you think a rewrite would take. The bad news is that your culture is pushing against making the fixes.
Take it one step at a time, and keep delivering.