It sounds like a category error, but it’s a real trade off baked into every SaaS with a relational database. This is the tradeoff behind the question “Should we use Foreign Keys in our database?”
Many don’t, based on the argument that Foreign Keys slow down data insertion. The database does extra checks when inserting, deleting, and updating data, which reduces throughput. Foreign Keys force devs to check the database and require that insertions and deletions go in a specific order. The database runs slower and development takes longer.
On the other side of the tradeoff, Foreign Keys prevent entire categories of database issues. They ensure that data is inserted and deleted in the correct order. When something goes wrong, Foreign Keys prevent data corruption. They are important, but optional, safety equipment.
Back to the tradeoff: Are Foreign Keys going to raise your DB and developer costs more than you’ll lose from customer churn and developer time spent remediating data corruption?
It’s a situation you never want to find yourself: Client support pulls you into a call with a large client, and they’re not happy. The website is slow! You need to fix it!
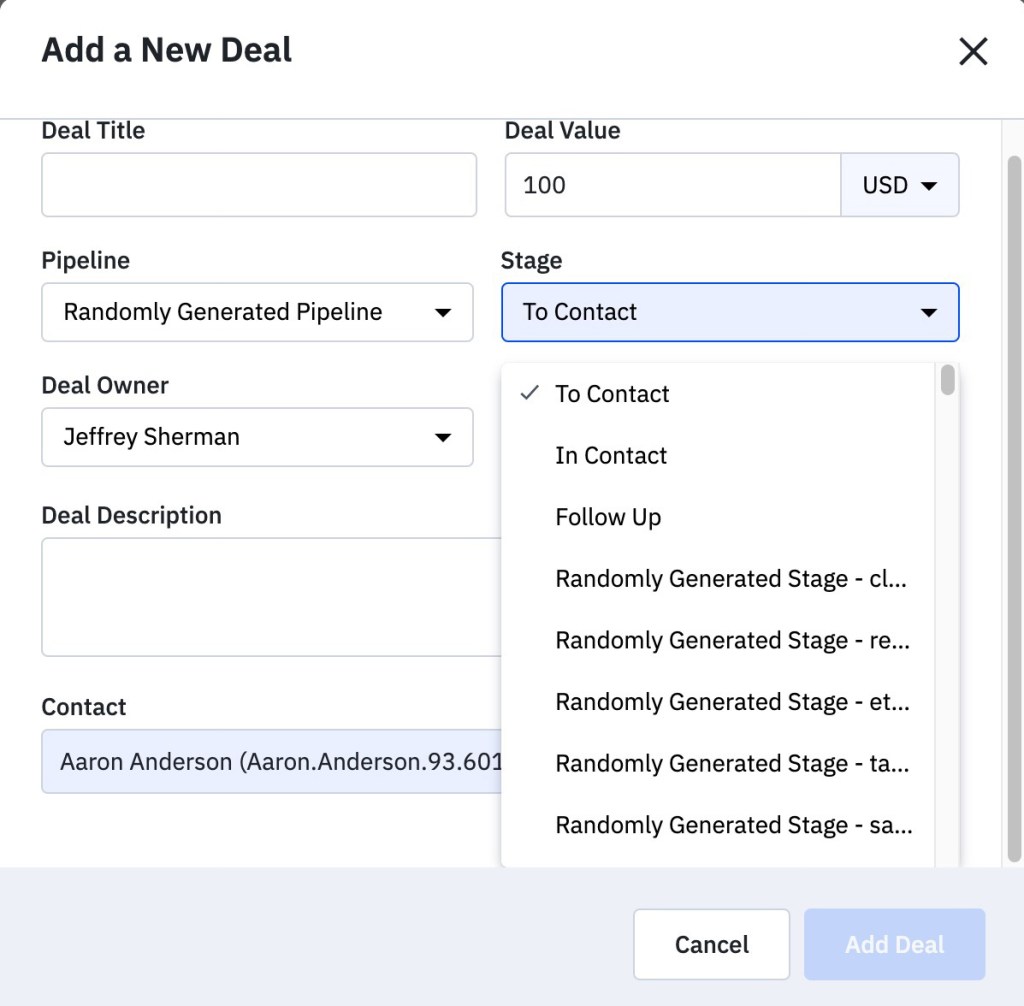
You know that websites can almost always be more responsive, but it’s not bad enough to justify this level of frustration. You start to ask questions. Where do things get slow? The “Add a New Deal” screen? That’s a simple page, there’s nothing going on there.
You go through the process of testing and pull it up on:
Your dev environment. You see a sub-second load time.
The test environment in production. There’s a sub-second load time there, too.
The client’s account. The load time is only 45 seconds.
How could that be? You wonder if the client’s database is overloaded. You check but the rest of their account is responsive.
That’s when you spot it — the stage dropdown has 25,000 elements.
You’ve been dropdoomed!
What is a dropdoom?
Here is an example of a 4 element dropdown that operates fine with no loading issues.
A dropdoom is a regular DROPDOWN UI element that is populated from a user-generated list. When the dropdown gets more than (roughly) 300 elements it will start impacting page rendering. And that’s when it switches from a dropdown to a dropdoom.
Add 500 stages and the same screen now takes 3 seconds to load.
Even on fast computers, dropdowns with more than a few hundred elements are going to slow down page rendering.
With the example covered above, the developers gave clients the ability to add custom deal stages. The assumption that the list would be short — how many stages can a deal have? Apparently 25,000! The clients generated so much data that rendering the dropdown became a performance bottleneck. Since only the client could see their own data, the developer didn’t know that the issue existed until the client called to complain.
Other examples of real dropdooms I’ve encountered include:
Assigning a task to an employee using a dropdown with all employees. This worked fine at first — until the company expanded to 2,000 employees. A combined total of 6 dropdooms added 20 seconds to the page rendering time. Using the task system became a chore, and eventually people stopped using it entirely.
A multi-select dropdown with all the tags a user has created. The page loaded in less than a second for clients with only a dozen tags. It became an issue when a client had 80,000 tags, increasing load time to over 30 seconds.
A survey with a dropdown to select your favorite European city. The dropdown showed a list of the largest 2,080 cities in Europe. That one element added 3 additional seconds to the survey’s load time.
The underlying problem
Most of the time fields will only have a handful of options. But some fields will always be growing, slowly at first, and then an exponential explosion. When things go bad, it isn’t the user’s fault for hiring too many employees, creating too many tags, or running a survey with too many cities.
You’ve handed the user experience to the users, but kept control of the interface. And sometimes, clients will abuse a feature on accident - those 80,000 tags were a result of a developer developing against the API.
The Solution
Instead of a simple dropdown, the safest default option is a type-ahead search. This requires users to have some idea what to type in order to make results appear.
Other options include:
The top 10 options plus a type-ahead option
An interstitial/pop-up with all the options in paginated results
A mix of top options and an interstitial option
There’s no magic solution, and it can be easy to blame the user. Users will always do things you don’t expect and might not make sense to you — but they’re not developers, you are. Making safe tools to protect the user from inadvertently impacting performance is your job. When you can think ahead and plan for possible outcomes, you can solve the problem before it even starts — and avoid a dreaded dropdoom.
I can’t blindly tell you why your software is slow and won’t scale. Everyone’s software and situation are different. If you’re stuck with no idea where to begin, these are my top 5 tactics for getting started when you don’t know what to do.
These tactics will improve the performance and stability of your system. They will help you understand the system’s constraints and bottlenecks. They probably won’t be the optimal solution to your problem, but they are a great place to start
Fix the errors in the logs and stop logging things that don’t matter. Not all errors are bugs, and not all bugs produce errors. Noisy logs that are full of meaningless errors make it hard to see “real” problems. Fixing or suppressing the noise will help you, learn the code, and fix a bunch of small problems. Exceptions are also slow, so this will make the system faster and more stable
Reduce the amount of db usage. Add caching for data that gets requested and doesn’t change. At scale even trivial queries add up. Ex: loading countries or states from a db.
Make work async - move it to queues. This allows you to keep api/ui moving and sets you up for eventual parallelism.
Make work restartable/idempotent/recoverable. Things break, make it easy to just try again
Shadow users. Learn what they think is important and broken. It probably isn’t what you thought.
This post is a much less dense discussion of the same topic with examples from airports. Airports use a multiple queue system at Security, and a priority queue at Boarding.
Security Has Multiple Queues
Most airports in the US have 2 or 3 different queues to get through the security checkpoint: Clear, TSA Pre, and regular. Agents help filter passengers into the different lines. Each line represents different priorities and has a different number of agents conducting security screenings. Once in a line, it operates as a FIFO (First in, first out) Queue. There’s no additional sorting.
This is a human driven Multiple Queue system, and it makes sense:
The workload is highly variable. There are peak times and slow times. Times that favor high priority people, and times that favor regular people. It is impractical to constantly shuffle the security checkpoint layout, so the system must accommodate all workloads.
You need to prevent resource starvation. Ie - you need to keep the regular line moving no matter how many people show up at TSA Pre
You want to minimize worker waste. Ie - when the TSA Pre line is empty, the agent starts screening people from the regular security line.
Security checkpoints are slow and frustrating. They are also well balanced to provide a simple, understandable, system that supports multiple priorities and minimizes agent idle time.
Boarding Gates Are Priority Queues
Boarding gates, where passengers wait to get on the airplane, are Priority Queues.
The gates operate under different constraints from the security checkpoint:
Nearly all passengers are at the gate when boarding begins
There are a set number of passengers
All of the high priority passengers should board before any of the regular priority passengers board. Unlike the security checkpoint, resource starvation is desirable.
The resources cannot be scaled. There’s one plane, one door, and one person through at a time.
The queues take multiple forms. They can be simple, like United’s
Or complex, like Southwest’s
The Priority Queues have a common structure. They have self sorting guided by signs and instructions. The ticket agent acts as a final filter, either accepting or rejecting people. The ticket agent (the worker) always runs at full capacity, while the queue itself is extremely inefficient and keeps people waiting a long time.
Since the plane only has one entrance, a Priority Queue is the only way to ensure that the high priority passengers get on first.
Reminder - We’re Really Talking About Scaling
Airports are designed to scale. They use Multiple Queues at the security checkpoint, because it fits the problem. They use Prioritized Queues at the boarding gate because it fits the problem.
Every SaaS has background workers. Processes that sync data between platforms, aggregate stats, run billing, send alerts, and a million other things that don’t happen through direct user interaction. Every SaaS also has limited resources; servers, databases, caches, lambdas, and other infrastructure all cost money.
Most SaaS go through three main phases as they mature and discover that queues are harder than they seem:
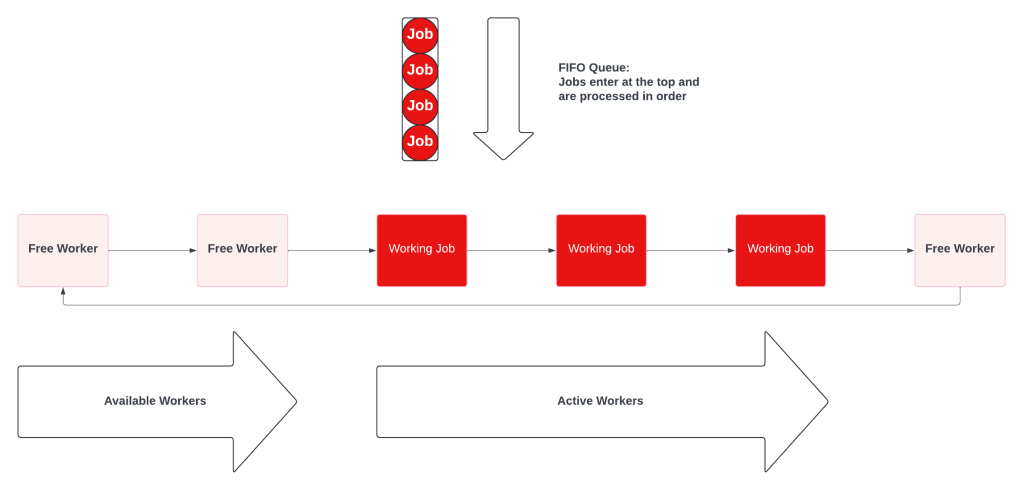
Whether driven by a database or proper queue, this high level system emerges:
Enter The Dream Of Priority
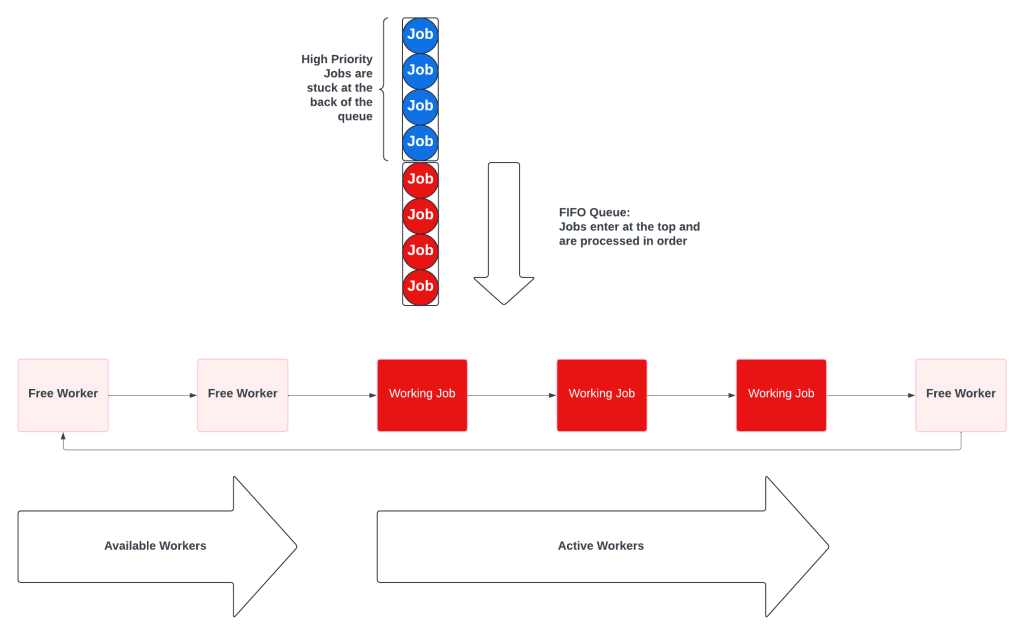
Because resources are limited and some jobs, and some customers, are more important than others, the idea of a Priority Queue will emerge.
“There are hours of work on the queue, and an important batch of jobs needs to be done now! If only some jobs can move to the front of the line.”
A Priority Queue seems like a great solution. The processes that create work can set a priority, add it to the queue, and sorting will take care of everything!
Unfortunately, what happens is that only high priority work gets processed. This is known as resource starvation. Low priority jobs sit at the back of the queue and wait until there are no high priority jobs.
Priority Queues only give you two options: add enough workers to prevent queue starvation, or make the priority algorithm more complex. Since resources are limited, engineers start getting creative and work on algorithms involving priority and age.
There is a much simpler solution.
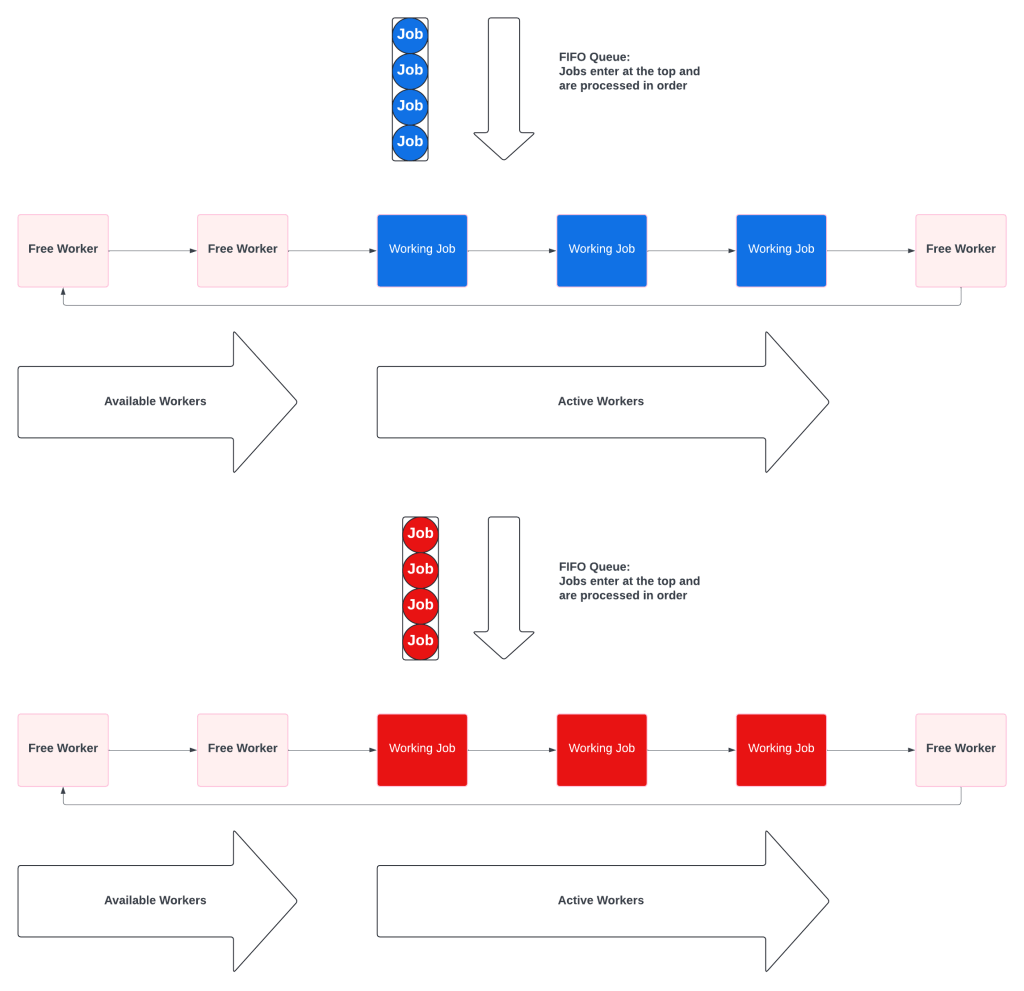
Multiple Queues Have Priority Without Starvation
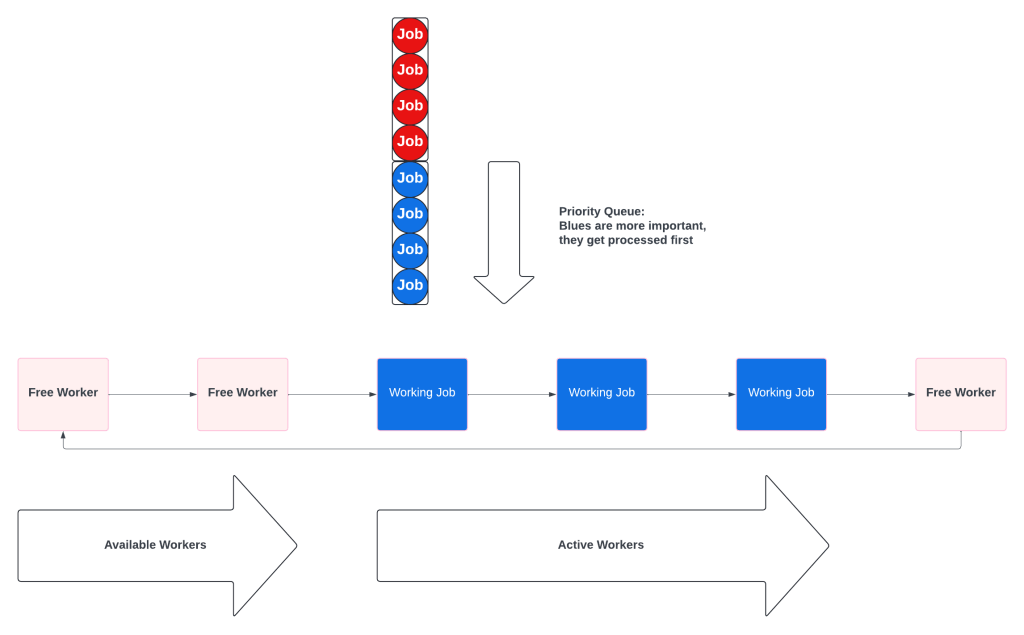
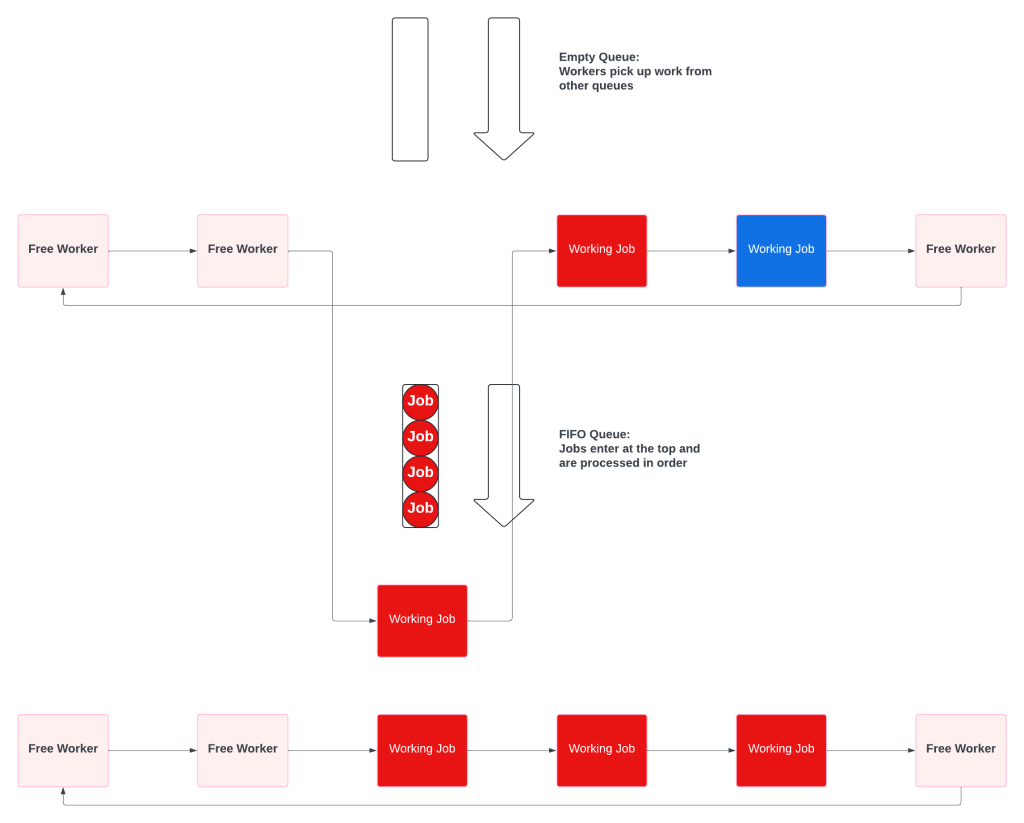
A Multiple Queue system is a prioritized collection of simple fifo queues. Each queue also has a dedicated worker pool, which prevents starvation. The key difference is that the workers will check the other queues when theirs is empty.
When all the queues have work, they behave like independent queues:
When the priority queue is empty, the priority workers pick up low priority tasks.
Multiple Queues solve priority in SaaS friendly ways:
No resource starvation. Some customers may be more important, but no customer ever gets ignored.
No wasted resources. High priority workers never sit idle waiting for high priority work.
Multiple Queues Push Complexity To Workers
Instead of having a complex Priority Queue, Multiple Queue systems push some complexity to the workers. Workers have to know which queue is their primary, and the order of the remaining queues.
Multiple Queues Have More Adjustment Options
Priority Queues only had 2 adjustment options: add more workers or adjust the algorithm. Multiple Queues allow much finer grained controls:
The number of different queues. Adding a new, super duper higher priority pool would not require a code change.
The size of the worker pool for each queue. Queues do not need to have the same size pools, and can be adjusted dynamically.
The relative priority of the queues. Priority becomes config, not an algorithm.
Conclusion - For SaaS Workers, Use Multiple Queues
Background workers are a common, critical, feature for most SaaS companies. Resource constraints make it impossible to run all background jobs as soon as they are created. Some jobs will have different priorities, which will require implementing either Priority Queues or Multiple Queues. Priority Queues sound like the correct answer because they describe the problem, but create resource starvation and ever increasing complexity. Multiple Queues are simple, safe from starvation, and much more effective for SaaS use cases.
There are at least a dozen places for variation in a single, successful, RESTful POST:
1. Time to establish a connection between client and server 2. Time to send the data between client and server 3. Time for the event to go up the OSI stack from physical to application layer 4. Time for the application to process the event. This is impacted by CPU, Memory, Thread models, etc. 5. Time for the event to go back down the OSI stack 6. Time needed to connect to the database 7. Time database needs to perform the action 8. Network time to and from the database 9. Time for the event to go back up the OSI stack 10. Time for the application to process the database’s response and prepare a response to the client 11. Time for the event to go back down the OSI stack 12. Time to send the response to the client
Let’s say that your SaaS has an SLA that all calls should return to the customer within 300ms. Looking at the system metrics, you see that your endpoint meets the SLA 95% of the time. What to make of the remaining 5%?
Common Causes are issues due to the nature of the system and will continue until the system is changed. In software, Special Causes are bugs and hiccups and will appear and disappear at random.
For our RESTful POST that needs to return in under 300ms, a source of Common Cause could be the physical distance between the client and server. If you are running on AWS in US-EAST-1, it is physically impossible to meet the SLA for customers in Asia. Round trip to places like Seoul and Tokyo is at least 450ms!
Requests from Asia will fall outside the SLA 100% of the time. The only solutions are to change the SLA or stand up an instance of your system closer to your Asian customers. You must change the system.
An example of a Special Cause could be an overloaded database. Some requests will be fine, others will break the SLA. The issue will go away once load decreases. The answer may be to change the system by increasing the size of the databases. Or keep the system the same and change the software to make the database insert asynchronous. The software change decouples the SLA from database performance.
Knowing that 5% of your requests break the SLA doesn’t tell you anything about Common vs Special Cause. Developers can fix some of the problems with software, but some can only be fixed by changing the system architecture.
Until you analyze and determine the source of your variation, you’ll be stuck on the Path Of Frustration. Pouring ever more resources into ever smaller gains.
Software development has strongly resisted learning about quality from physical manufacturing. After all, our product isn’t physical and isn’t bound by the same constraints as the physical world. One of Deming’s core messages is that quality will increase as variation decreases. This applies to software too!
Even a simple CRUD app has tons of variation.
There are at least a dozen places for variation in a single, successful, RESTful POST:
Time to establish a connection between client and server
Time to send the data between client and server
Time for the event to go up the OSI stack from physical to application layer
Time for the application to process the event. This is impacted by CPU, Memory, Thread models, etc.
Time for the event to go back down the OSI stack
Time needed to connect to the database
Time database needs to perform the action
Network time to and from the database
Time for the event to go back up the OSI stack
Time for the application to process the database’s response and prepare a response to the client
Time for the event to go back down the OSI stack
Time to send the response to the client
Most of the time, things like traversing the OSI stack, CPU and memory management take minimal time and have minimal variation. One major source of variation is when the JVM or CLR enters a garbage collection cycle and halts execution for several seconds.
Even when every request succeeds, some requests can take 100x or even 10,000x longer than the median. Does that variation matter? Sometimes.
In rare cases, like High Frequency Trading, this variation can be the difference between earning millions and going bankrupt. Most of the time the variation is a sign of system health and doesn’t matter much in isolation. But if the variance gets bigger, week after week, release after release, it is a sign that your system has long term health problems.
Just because the code does the same thing every time, doesn’t mean that it executes the same. Variation applies to software and we can learn a lot from physical manufacturing.
Writing a Run Book can be your first iterative step towards mitigating recurring problems. Recurring problems can cause massive productivity problems, but don’t get fixed because the immediate issue is elsewhere.
For example, background worker systems rarely fail on their own, instead some unique situation will cause the workers to get stuck, the controller to get confused, or the queue to be poisoned. Each time, there are really two issues. The bespoke issue that broke the background processes and the recovery of the background worker system.
Since each new failure is unique, there is a tendency to treat the background system recovery as a unique problem too. This increases recovery time and prevents you from learning from past mistakes. Because the bug isn’t in the background system itself, there is often no motivation to spend time on the code. Fix the bug, restart the system, and move on with your day.
Enter the run book.
Write down the steps needed to mitigate the problem. This is for humans, so it can be an open ended description of what to look for, it won’t be very programmatic.
Once you have it, keep iterating. Add code snippets, descriptions, and flow logic.
As you iterate, you will notice that some parts of the process can be scripted, or even automated.
Iteration after iteration, more and more of the run book will become code, which makes it easier to code up the remaining pieces.
Will you be able to iterate the recurring problem out of existence? Maybe, maybe not. But with a run book and a plan, you will make progress and not be waiting for the next outage to wreck your day.
Messaging systems don’t change the fundamental tradeoffs involved in data loading, but they do add a lot of opinionated weight to the choices.
First, messaging and streaming have a lot of potential meanings and implementations. To overgeneralize, there are queues, where each message should be read once, topics, where each client should receive each message, and broadcast, where there are no guarantees about anything.
Queues and topics work as polling loops within your software. Broadcast messaging comes directly to the machine at the network level; the abstractions are highly dependent on implementation.
For the rest of this article I’m going to cover queues. I’ll cover topics and broadcast in future articles.
Loading Patterns with Queues
The main feature of a message queue is that you want each message to be processed exactly once. This requires clients claim messages when taking them off the queue, notifications back to the queue when messages have been processed, and a client timeout, after which a claimed message will reappear at the head of the queue.
A client has to connect to a queue, ask for some number of messages and indicate how long it will wait for the max number. For example, AWS’ SQS the defaults are 10 messages or 30 seconds. The client will block until 10 messages are available, or it has been waiting for 30 seconds.
Set the message request too big and you will wait while the queue fills. Set the timeout to long and the first few messages will get stale while the client waits. You need to balance the time cost of polling the queue against the cost of having your workers idle.
The main concern however, is visibility timeouts. If your client grabs 10 messages and has a 30 second timeout it absolutely must finish all 10 in under 30 seconds. After 30 seconds the unacked messages will be released to the next waiting worker and your message will be processed twice.
Optimizing worker counts, polling settings, and timeouts requires maximizing execution consistency. When working at scale, how long an action takes matters much less than how consistent the timing is.
If your system is drinking from a firehose, you need to push everything towards a Pre-Cache model. Pre-Cache pushes data loading out of the critical path, which gives the most consistent timing for message processing.
Having fully Pre-Cached queue processors is rarely possible, there is too much data and it changes to often. Read Through Caching is the practical alternative.
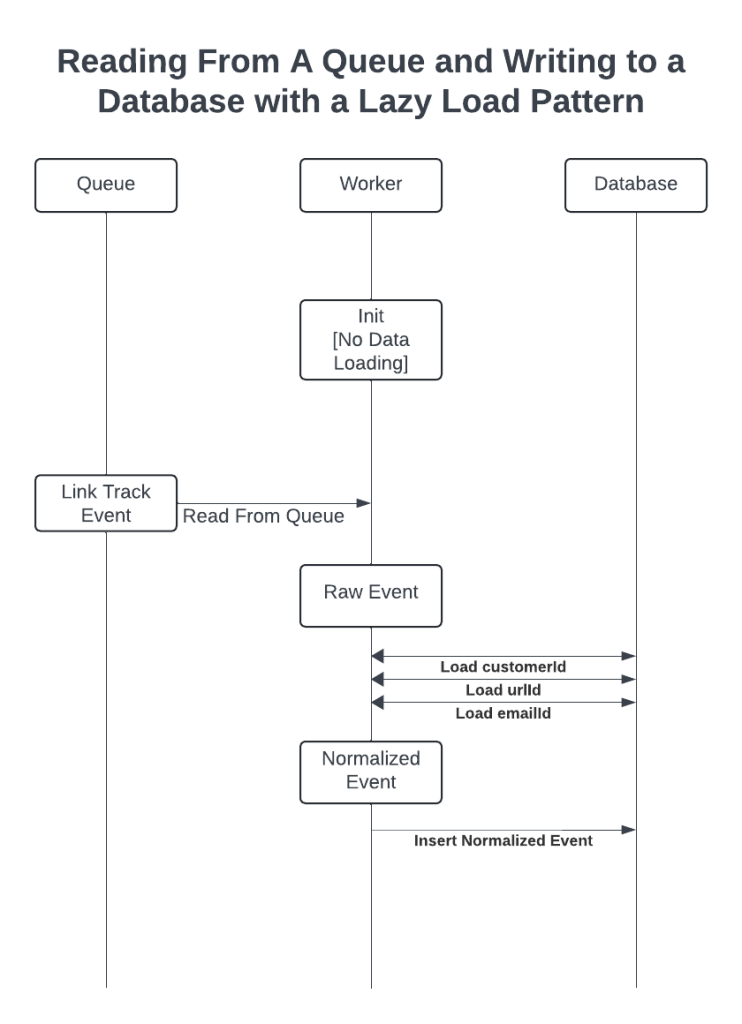
Link Tracking Example
Link Tracking, recording when someone clicks on a link, is a common activity for Marketing SaaS. I’m going to use a simplified version and walk through each of the data patterns.
At a high level, we have a queue of events with 4 pieces of data that describe the click event: Customer Name, URL, Email, and Timestamp.
We want to process each event exactly once, as quickly as possible, and we don’t care about the order messages are processed. However, we can’t insert directly, we need to normalize Customer Name, URL, and Email into customerId, urlId, and emailId.
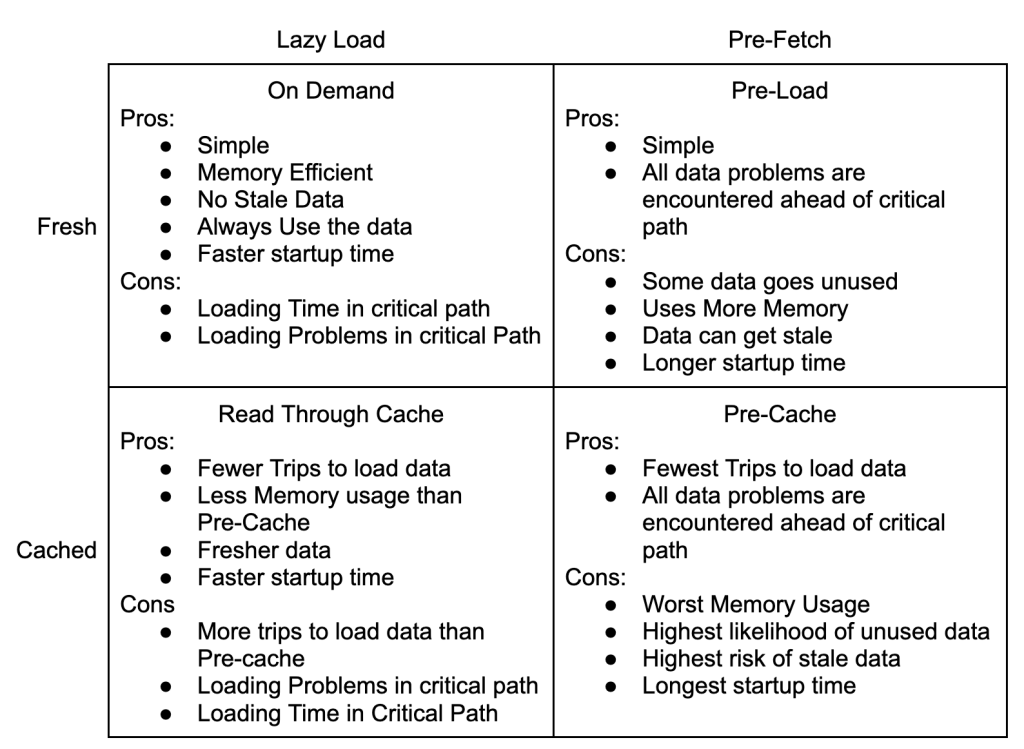
Lazy Load
The nice things about the Lazy Load pattern is that it starts quickly and is simple to understand.
Unfortunately, every event requires 3 trips to the database to normalize the data. This adds load to the database and has highly variable processing time.
It’s a fine place to start, but a terrible place to stay.
Pre-Fetch
The Pre-Fetch pattern separates fetching the data into a separate step from execution. In this example, the worker would be attempting to normalize multiple events at the same time. Once an event has been fully normalized, it is inserted into the database.
Pre-Fetch adds a lot of complexity because the workers now have internal concurrency in addition working in parallel with each other. This might be worth it if the data was being composed from different resources in a micro-service architecture and the three calls could be done in parallel. In this example though, you would be pounding the database.
Pre-Cache
The great thing about a Pre-Cache model is that there are no reads against the database during processing. It is read-only during init, and write only from the queue. That will really help the database scale!
Pre-Cache is impractical in this use case though. We might know the full set of customers at startup, but urls and emails are open ended. Pure Pre-Cache setups require that all of the data be known before starting. That can work for things like file imports and trading systems, but not link tracking.
Read Through Cache
The Read Through Cache Pattern is likely to be the best option for our use case. It is more flexible than the Pre-Cache Pattern and much friendlier to the database than Lazy Loading or Pre-Fetching. It pushes complexity to the cache where there are lots of great solutions. Most languages have internal caching mechanics, and external caches like memcached and redis are widely supported.
Conclusion
Reading from message queues is a common problem and usually requires composing data from a database. What’s the best way to load the data? As always, the right data loading pattern depends on a your conditions and assumptions.
Lazy Loading is always a decent place to start because it is simple. Performance, cost, and scaling constraints will push your design towards Read Through Caching and Pre-Caching. Pre-Fetch models are likely to be more effort than they are worth because they add a second source of concurrency and complexity.
Remember, requirements change over time, so will the best solution to your problem!
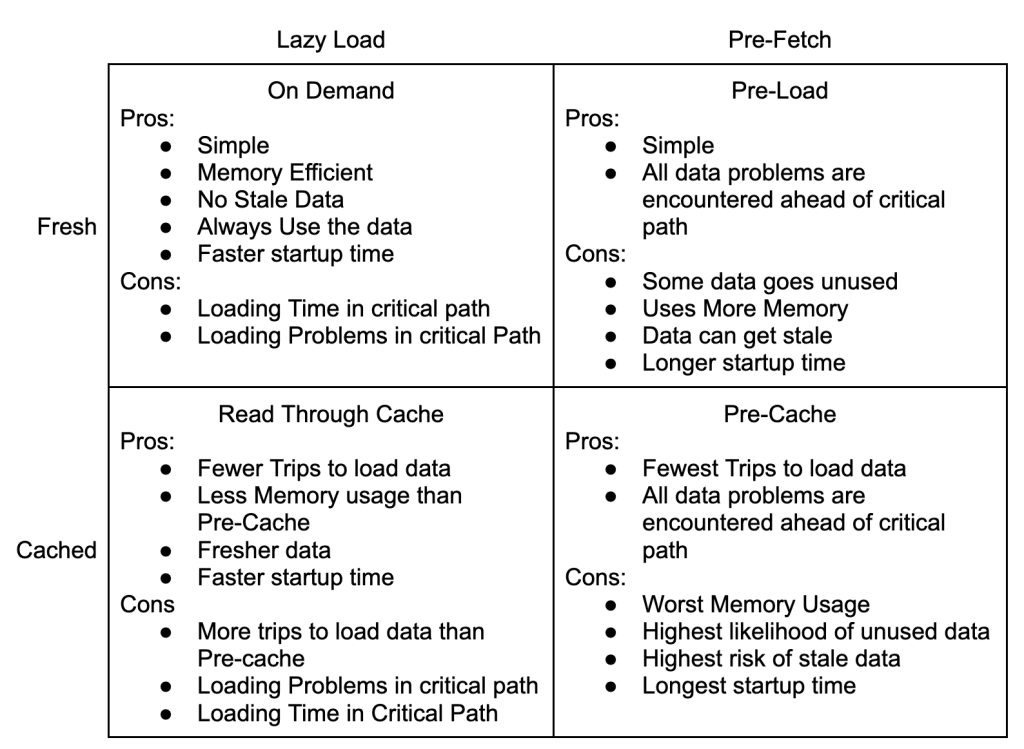
The Four Patterns Of Data Loading are about two main trade offs: simplicity for performance, and freshness for execution consistency.
This may seem odd because the quadrants are defined by loading and caching strategies, not simplicity, performance or execution consistency.
Simple or Performant
The decision to use caching is about trading simplicity for performance. You can simply load the data every time you need it. If you’re using MySql on AWS, a basic query will take about 2ms to return. The pattern is very simple and self contained: load data when needed.
Caching, saving data for reuse, improves performance by reducing the time it takes to use the data again. In exchange, you have to think about your code and determine:
Will I use the data again?
Is the data likely to change in the DB while I have it cached?
If the data does change, do I want to use the latest version or the version that the process has been using so far?
How much server memory will I need for the cache?
Example - Adding a Tag to a Contact
Imagine a simple operation, adding a tag to a contact. The tag is a string and the contact is represented by an email address. You need to transform the tag and email into ids and store them in a normalized database table. For simplicity's sake, let’s say all DB operations take 2ms.
There are 3 DB Operations
Load the contactId based on email
Load the tagId based on tag
Insert into contact_tags
With the On Demand access pattern, we do each action every time. This requires 3 trips to the DB for 6ms.
Similarly, with the Pre-Load pattern, we spend 2ms pre-loading the tagId, and each operation takes 4ms.
Using a Read Through Cache, we store the tagId after the first load. The first operation takes 6ms and each additional operation takes 4ms.
Finally, with the Pre-Cache pattern, we spend 2ms pre-loading the data and each operation takes 4ms.
1 Tag, 1 Contact
1 Tag, 10 Contacts
10 Tags, 10 Contacts
Init
Exec
Init
Exec
Init
Exec
On Demand
0ms
6ms
0ms
60ms
0ms
600ms
Pre-Load
2ms
4ms
20ms
40ms
200ms
400ms
Read Through Cache
0ms
6ms
0ms
42ms
0ms
420ms
Pre-Cache
2ms
4ms
2ms
40ms
20ms
400ms
Freshness or Execution Consistency
The next tradeoff to consider the value of fresh data vs execution time consistency. This goes beyond questions of caching, it also affects whether you can use the Pre-Load strategy at all. A big advantage of the Pre-Load and Pre-Cache strategies is that the execution time is lower and less variable.
Stock trading software is designed to pre-load as much data as possible and can spend minutes initializing so that the actual buying and selling happens in microseconds. Similarly, internet ad networks like Google’s demand responses in 100ms or less. Having consistent execution times in each piece of your software makes it much easier to monitor performance for signs of trouble.
Security software and reporting sit on the other end of the spectrum. It doesn’t matter if a user had permission 5 minutes ago and everyone hates waiting for report data to update. In these cases the variance for each response is much less important than getting the most recent data.
Some data never changes once it has been created. In the example above of adding a tag to a contact, both tagId and contactId will never change during your program’s execution. Generally, anything with ‘id’ in the name is safe to cache. On the other hand counts, permissions, and timestamps change all the time.
Strategies can be good for some situations and terrible for others. Sometimes it depends on expectations vs money.
Ids and static data
Permissions
Counts and Reporting
On Demand
Bad
Good
Good, until it doesn’t scale
Pre-Load
Good
It depends on time elapsed
It depends on time and money
Read Through Cache
Good
It depends on time elapsed
It depends on time and money
Pre-Cache
Best
Bad
It depends on time and money
Conclusion
The “right” data loading pattern is a moving target. Remember that in the beginning load is low and there are continuous changes. Simplicity is always a great choice when there isn’t enough scale to justify complexity.
As software matures two trade offs emerge: Simplicity vs Complexity and Freshness vs Consistency.
You’re changing the software for a reason. When you consider the tradeoffs it should become clear which patterns will help solve your problem.