Are bad practices around testing and releasing cultural or technical? "Bad" changes as a company grows and matures, and what was bad for a startup may not be bad for more established companies. Similarly, holding on to startup practices to long can have a devistating impact on accountability.
If you've ever wondered why your company can't kick bad habits, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
Welcome to “Your Edge Case is Showing!” In this series I discuss real world software edge cases that happened to me. The goal is to have a constructive analysis of the problem, the thinking behind it, and why it probably hasn’t been fixed despite being broken in production. As a general disclaimer - I’m using the software because I like the company and I’m a customer.
—---------
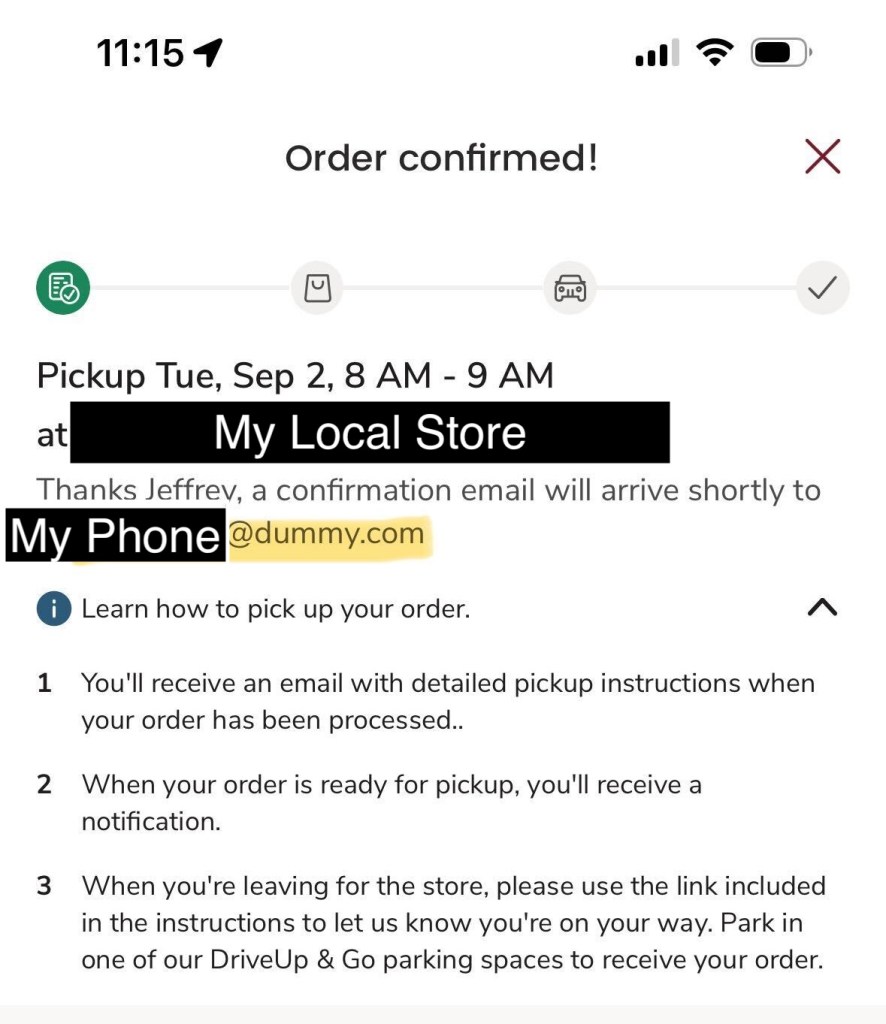
I do most of my grocery shopping at Jewel Osco, they have mastered the number one most important consideration: They are the closest grocery store to my house. They also have a really good selection of apples, are cheaper than their competitors, and they are open late. What they don’t have is a good mobile app.
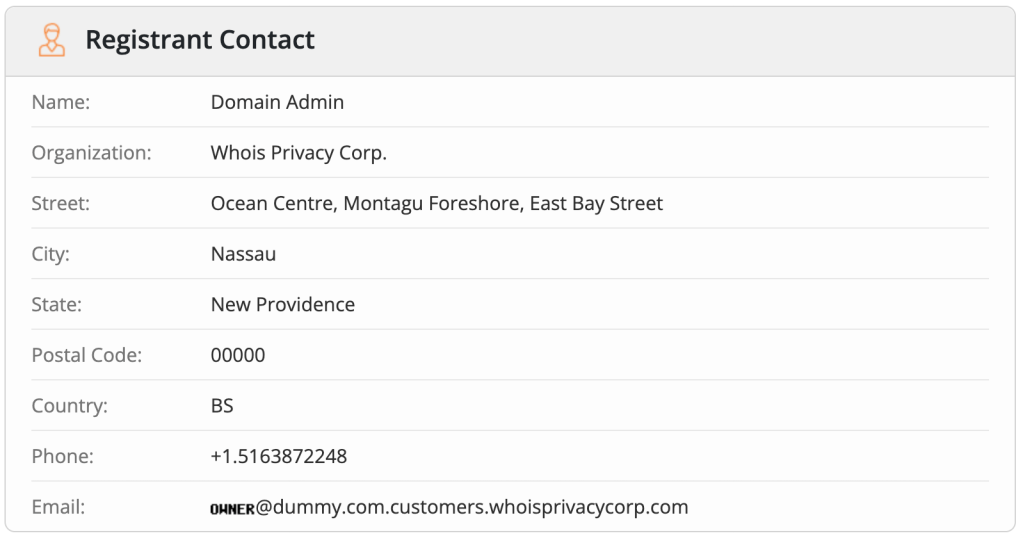
After placing my latest online order I noticed that they were sending a receipt to [my phone number]@dummy.com
My shopping app account is based on Jewel’s rewards program, and I signed up for the rewards program with my phone number. I have never given Jewel my email, mostly because they never asked!
My guess is that email is a required field in the app’s data model. So the developers handle the missing data using what they have, my phone number. Adding “@dummy.com” to make a technically valid, but obviously fake email address.
Why Doesn’t It Get Fixed?
The app has a LOT of problems. It’s unstable, it’s slow, and it apparently sends receipts to anonymous domain owners in the Bahamas.
I can imagine managers prioritizing stability and pushing edge cases like email receipts to the side. After all, if no one can use the app, it can’t leak any data! Fixing bugs is also much easier than changing fundamental data constraints. I wrote a whole series of articles on the topic!
Wildly discounting the cost of privacy leaks is a common mistake!
I have submitted a bug report. Fingers crossed this is not what it looks like, or will be fixed very soon.
Start small, get feedback, and keep going! This week, Day Martin, founder of Swayday, shares her company's iterative journey. Swayday began with motion games aimed at causal gamers and has iterated to their current mission of using motion games to improve educational outcomes for children with ADHD.
If you've ever wondered what it is like to iterate as an entreprenuer, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
Project failures are an inevitable part of a software developer's life. While failures are inevitable, learning and recovering value from the wreckage is entirely optional. In this episode Isaac and discuss ways to learn more, reuse more, and minimize the scope of project failures.
If you've ever had a project fail and wondered "now what?", this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
Ever struggled to get people to notice incremental changes? Small and gradual is great for increasing velocity and reducing risk, but they risk getting lost in the noise. In this epsidoe we discuss how gathering metrics results in better outcomes and team visability.
If you've ever wondered how to show steady improvement over time, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
Does AI invert the Testing Pyramid? Does it still make sense to have lots of unit tests, fewer integration tests, and very few end-to-end tests? As AI makes it easy to write end-to-end tests do the old rules still make sense?
If you are wondering how AI impacts writing and running tests, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
Spriha Tucker, Field CTO at BuildKite joins us to talk about feedback loops in iterative development. Spriha explains how CI/CD is all about feedback loops and de-risking the development process.
If you've ever wondered how you can have CI/CD and still have massive projects fail, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
Why do abandoned projects and failed rewrites have code that lingers on forever?
If you've ever wondered why it is so hard to shut down old systems, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
Sure, the software part of the software rewrite is going to fail, but that's just the beginning. In this epsiode of Never Rewrite, Isaac and I work through the social and emotional ramifications of failed rewrites.
If you've wondered about the pressures that rip teams apart, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
You don't have to chose between a Rewrite and Iterative Improvement. You can also ask, "Do I even want a better version of what I have?" Maybe neither choice is right for you, and you need a pivot.
If you've ever looked at some code and said "Not only is this a mess, but it doesn't do what I want", this is a great episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!