Paul Stack shares his experiences transforming his company from individual server based logs, to a unified log stream searchable with Grafana. Paul walks us through the stepwise iterations: going from single machine logs to aggregated, how aggregating the logs overwhelmed the service so they brought in kafka, how kafka made it difficult to restart, and so on. This story is pre-cloud and years before the concept of Open Telemetry; Paul's deep dive sheds light on some of the very difficult problems that modern observability stacks make easy.
If you've ever wondered about how aggregated logging systems evolved, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
A static analyzer can go through code and find big-O type problems. A developer can go through and refactor the code to make it run more efficiently.
Neither of these tasks requires much context about the larger system.
For example, a function can take a list of contacts and load each one from the database. After loading the contact, it can then load each activity that the contact has done, one at a time. This is a standard nested for loop with O(n^2).
With no further context, you could modify the code to load all of the contacts in a single query. You could then load all of the activity with a second query.
From the perspective of querying the database, the function would go from O(n^2) to O(1). The only context you would need to know is if N could be large enough to exhaust your software’s memory. (There would still be O(n^2) work in memory to assemble the data objects, but that is negligible against the cost of DB calls)
But if you had deeper knowledge you might realize that you don’t need the data in the first place. No database calls are not only faster, but deleting the code is a whole lot easier than refactoring.
AI and other tools make static type efficiency optimizations much easier; but they can’t ask “Should the code even be doing this?” System context is where developers still shine.
What are the signs of a failing rewrite? This week Isaac and I discuss the signs to watch for when you're on a team doing a rewrite.
If you're on a rewrite and wondering if the project is in trouble, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
Nick Stinemates from System Initiative joins us to discuss his experiences with software rewrites. We cover a lot of ground in the episode, from the difference between rewrites and refactors, the importance of incremental changes, and team dynamics during rewrites.
If we've been confusing you about the difference between a rewrite, and iteratively replacing all of the code over time, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
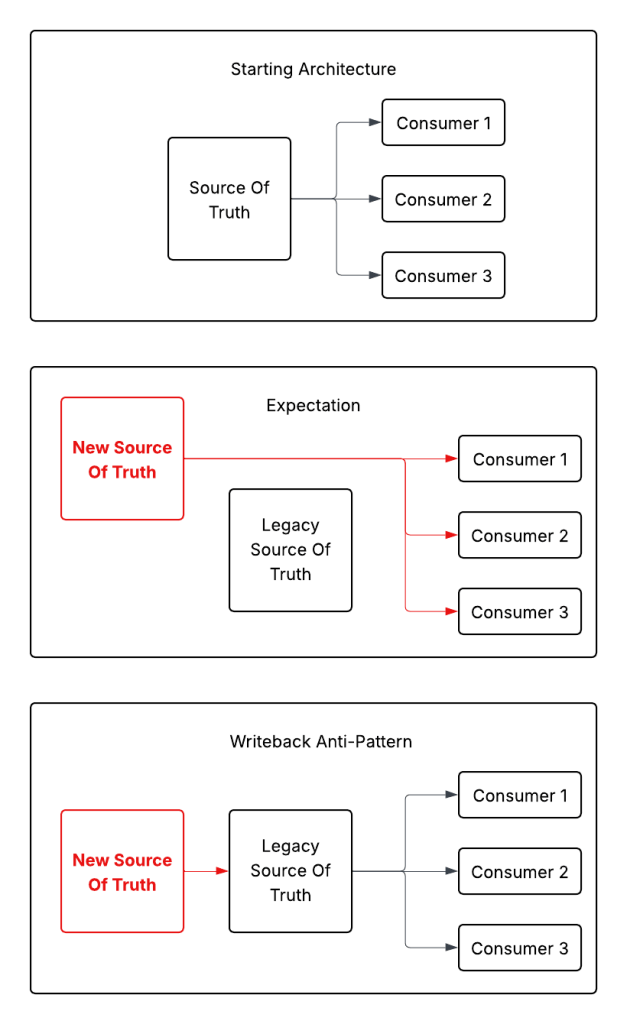
The Writeback Anti-Pattern is when a new Source Of Truth has to write data back to the legacy Source Of Truth because consumers are still getting data from the legacy source.
The Anti-Pattern allows you to pretend that the new system is indeed The Source Of Truth, and the legacy system has become an adapter. This is a lie that lets teams declare success and get the new system into production.
The reality is that the new system is really just another bolt on to the old. The new system now needs to transform all the inputs into the old format, creating tons of technical debt. You have the data model you want, the data model you don’t want, and all the business logic in between.
Another way to explain it, is that the new system tried to do a strangler-fig backwards. Instead of inserting itself between the old system’s outputs first, the new system intercepted the inputs. For the strangler-fig pattern to work it needs to replace the outputs first, or both the inputs and outputs simultaneously. Redirecting the inputs first leads to The Writeback.
This week Isaac and I explore the complex trade-off between providing immediate relief versus investing time and resources into finding and fixing the underlying bug. Sometimes, fixing the bug is the wrong choice!
If you've ever agonized between fixing a bug, or just mitigating and moving on, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
"I'm not technical, but I think the developers I've hired are BSing me. How can I tell?"
This is often the first question Dustin and Isaac get when talking to potential clients. In this episode we work through issues with trust, communication, and how iterative development encourages both. Dustin reveals his framework for keeping communication open and identifing red flags in developer behavior.
If you've ever wondered what developers were doing, but were afraid to ask, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
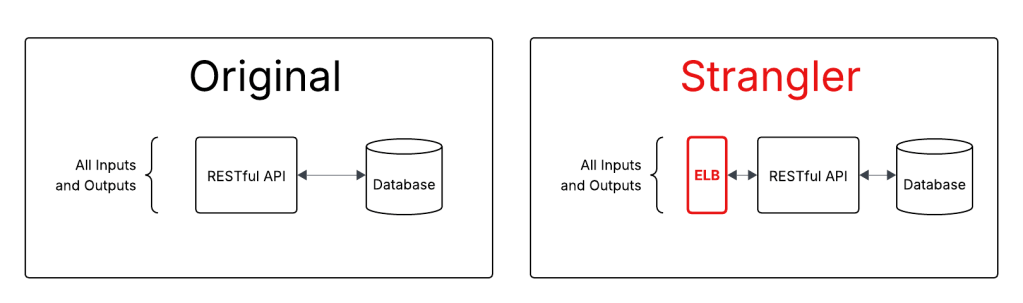
The Strangler-Fig is a critical refactoring tool. The implementation sounds easy: wrap the existing code with the strangler, and replace the references over time. This glosses over an important implementation detail - there’s an order to wrapping code: The outputs have to go before the inputs.
Strangler-Fig Examples Are Single Step
Oftentimes you can fully wrap the strangler around the existing code in a single step. For example, Amazon’s Elastic Load Balancer can be used as a Strangler. It instantly proxies all requests to a service; and makes it easy to migrate routes to a new service over time.
Systems with Multiple Outputs Need Multiple Stranglers
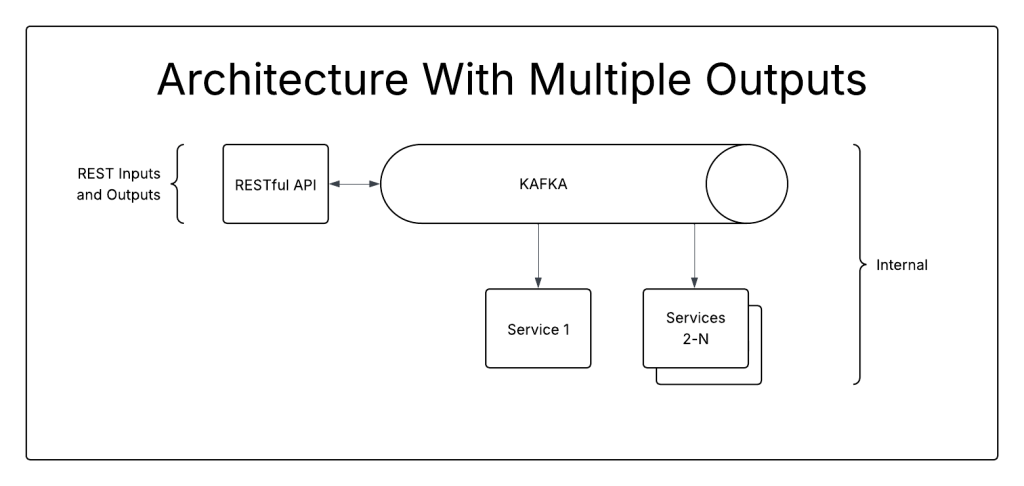
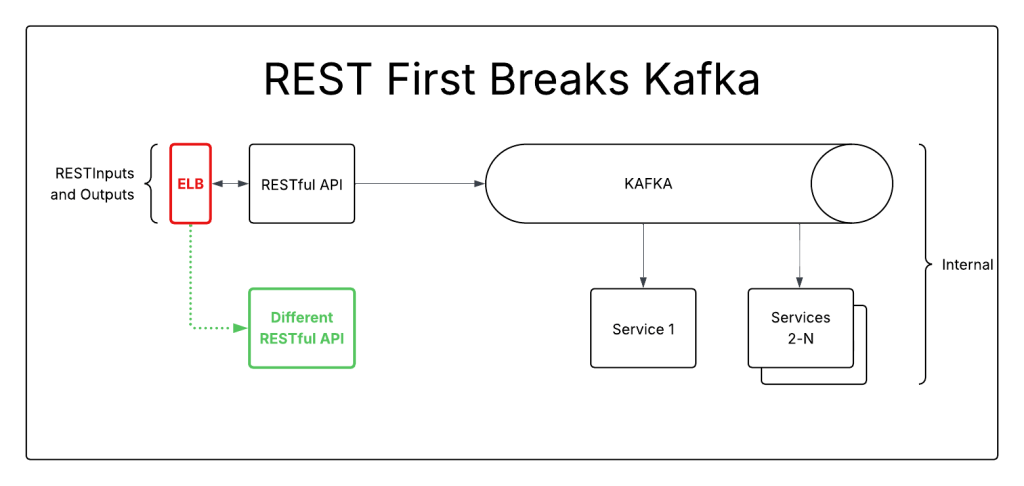
That works great for simple architectures with a single entrance and exit. But what about something more complicated? What if your system has a RESTful interface for data inputs and then publishes events onto Kafka?
Because the system has one input and two outputs, a single strangler like ELB is insufficient.
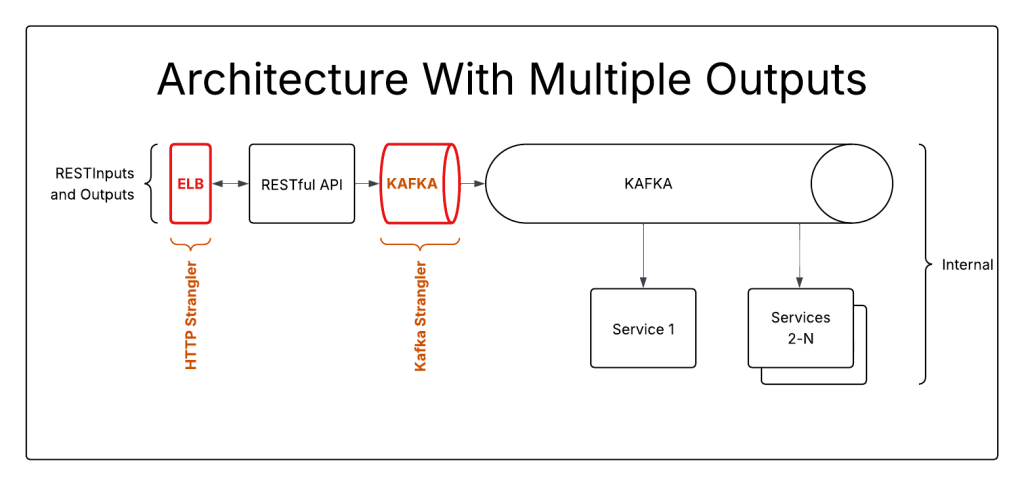
This system requires 2 different strangler-fig implementations. An ELB, or web proxy, to handle RESTful communication, and kafka to proxy the communications from the service to kafka.
Even in an ideal world, where you can put the proxies into place with just simple config changes, this is a two step process. More realistically, there will be weeks or months between setting up the first strangler, and the second.
The Partial Strangle Limits Options
Remember, the goal of the Strangler-Fig pattern is to squeeze out the original system over time.
A partial strangle limits your options.
Doing ELB first lets you redirect RESTful inputs and outputs, but won’t populate the kafka stream. This will break your system if you attempt to migrate any endpoints. The Writeback anti-pattern, where the new system will write to the original system for the benefit of downstream listeners, is a common solution.
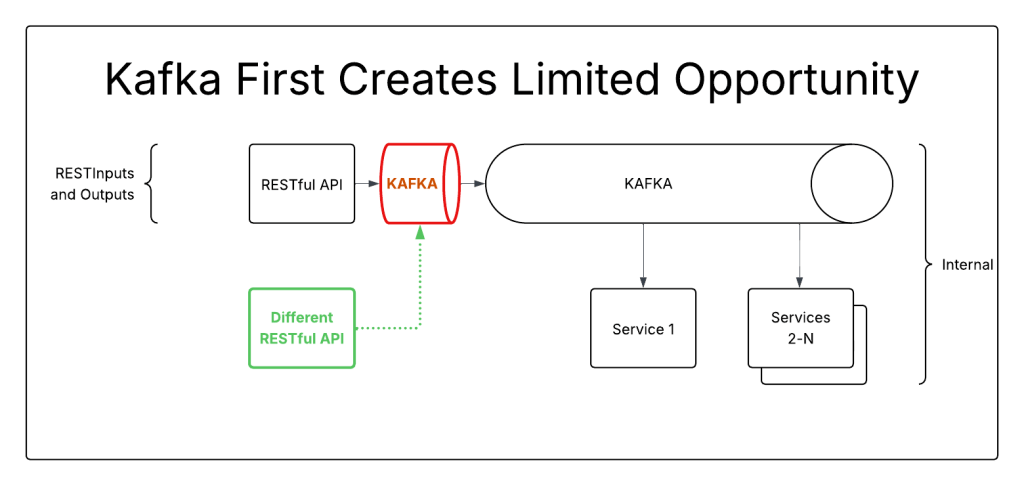
Putting the first strangler around the Kafka connection won’t break anything, and creates limited opportunity for migration. Any messages that can be generated outside of the REST inputs can be migrated in this state.
For Complex Systems, Strangle The Outputs First
The Strangler-Fig pattern should be in every developer’s toolbox; there is nothing better for reducing risk during refactors. If you have a complicated system, with more than one type of output, you will need multiple stranglers, and the order of application is critical. Apply the stranglers to pure outputs first, input/output groups second, and pure inputs last.
Applying the stranglers in the wrong order will lead you to implement anti-patterns like The Writeback. Far from making the transition easier and lower risk, the anti-patterns will make your work harder and riskier.
Guest Dan Hon joins us to discusses the complexities of rewriting government software. Dan discusses the importance of understanding legacy systems, the role of ideology in software development, and the need for transparency and user-centered design. We also touch on government specific challenges that come with modernization of government services.
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!