Transformation expert Sophia Rosa rejoins the show to deliver a master class on the human factors behind changing organization. Bad news for developers, changing code is the least important factor.
If you've ever tried to drive change by changing technology, and failed, this is the episode for you!
Once upon a time web browsers worked differently. Every browser supported different features and developers had to work hard to ensure that websites worked more or less the same on each one. These difficulties were mostly on purpose! Incompatabile browsers were product differentiators, and had moats!
If you want to hear about the "old days" of 10 years ago, this is the episode for you!
Back when cpus, memory, and hard drives were limited bit masks were the most efficient way to store flags. Why store one flag in a variable when you could store 8 flags in a byte? Why not do the everything the most efficient way possible? Because cpus, memory, and hard drivers aren't limiting factors anymore.
If you've every wondered about software optimizations that aren't worth doing anymore, this is the episode for you!
How do you explain the status of a project? As you progress and learn more, is it even the same project? These are hard questions about the transmission of true and accurate information. Or, you might just be trying to hide that the project is falling behind schedule.
If you've ever wondered about the tricks and obfuscations used to hide a project's true status, without exactly lying, this is the episode for you!
Are you ready to hire a developer to scale your business? Are you sure? In today's episode Isaac walks us through how he attempts to convince perspective customers not to hire him!
If you've ever wondered if you're ready to hire consultants to help you scale, this is the episode for you!
What happens to new bugs in a system being rewritten? Do they get fixed in both systems, just the new system, or neither systems? In this episode Isaac Askew and I explore how rewrites create accountability black holes that encourage bugs to linger.
If you have ever wondered why annoying, but simple, bugs don't get fixed, this is the episode for you!
AI is great for coding! How is it doing outside of coding? In this episode Isaac and Dustin dig into AI's impact on legacy system development, team dynamics, and other human factors beyond the code.
If you've been wondering how AI is changing legacy development, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!
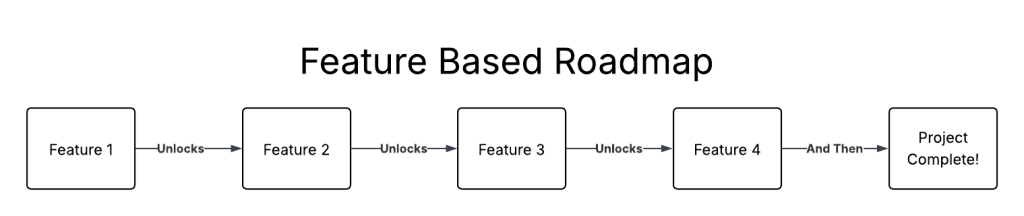
The road to hell is paved with good intentions; the roadmap is written in features.
The Road To Hell Is Paved With Good Intentions points to the common disconnect between someone’s intent, and the result of their actions. Good intentions, and good actions, do not guarantee good outcomes.
Roadmapping features has the same disconnect between intent and results. Good intentions, and good features, do not guarantee good outcomes.
Each feature makes sense, and is good by itself.
The problem is that the goal isn’t a feature, a whole series of features, or even projects. The goal is the outcome. Roadmaps full of features don’t track the progress towards an outcome, they track progress on features.
Roadmaps based on features present a linear path. Each feature unlocks the next. This, then that, and then that, until the project is complete.
Customer feedback isn’t baked into the process. Will all of the good features lead to good results? Probably not!
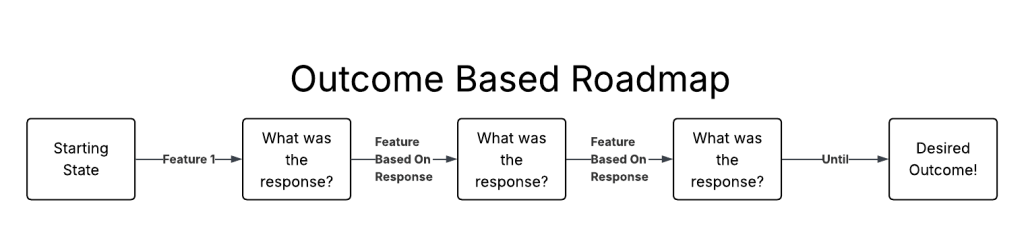
The opposite of roadmapping features, is roadmapping outcomes. This requires getting clear on where things are, where they need to end up, and the mechanisms that drive change.
The only feature that comes out of an outcome based roadmap is the first one. The first attempt to change the system. After that? Depends on the outcome of the feature!
Outcome based roadmaps are built on mechanisms that can drive change, and feedback loops. The features are unknown because the impact of each feature is unknown.
A roadmap built of features is like a road to hell, paved with good intentions.
Are rewrites a failure of the imagination? Are they the inevitable consequence of deferred maintaince? Is it possible a rewrite to succeed in such a way that it validates the choices that led to a rewrite? Mark Mandau rejoins Isaac and me to discuss how managers and leaders look at the question of rewrites.
If you've ever wondered how managers and leadership evaluate rewrites, this is the episode for you!
Watch on YouTube or listen to it at Spotify, Apple Podcasts, or your favorite podcast app, and let us know if you have ever been involved in a rewrite. We would love to have you on the show to discuss your experience!