I've used dozens of config systems in my career, heavy XML, lightweight INI, and more "Config is easy, I'm just going to write my own" disasters than I care to count. Recently I have been working in Node and deploying to Heroku, and I found what may be my favorite config system of all time.
Node-Config is a JSON based hierarchical system that plays wonderfully with Heroku's Environment variable based config.
What does a hierarchical system mean?
Imagine you are working on a system that can be run
local,
dev, or
production, with different database and remote services. When running locally your config might look like this:
{
"dbConn": "DB Running locally on my laptop",
"webapp": {
"port": 8080
}
},
dev also runs on port 8080, but uses a shared database. Instead of overwriting everything, you only have to specify the deltas:
{
"dbConn": "Shared database location",
}
Node-Config used the "NODE_ENV" magic variable to know which environment you are running, but no matter which environment you are running,
config.webapp.portwill be 8080.
Where does Heroku fit in?
Heroku injects config variables into the system as environment variables at run time. When using a Heroku Postgres database, they not only manage the system, but they will also automatically rotate the connection details periodically. That's great, but if means you can't have a static config file.
Well
Node-Config ALSO supports environmental variable overrides!
You need to create a config file called
custom-environment-variables.jsonand place it with the rest of your config. Instead of specifying values, you specify the environment variable names! Continuing our example:
{
"dbConn": "HEROKU_POSTGRESQL_NAVY_URL",
"webapp": {
"port": "PORT"
}
},
PORT is Heroku's default PORT, and
HEROKU_POSTGRESQL_NAVY_URL is a environment.
Your Heroku config dashboard will look something like this:
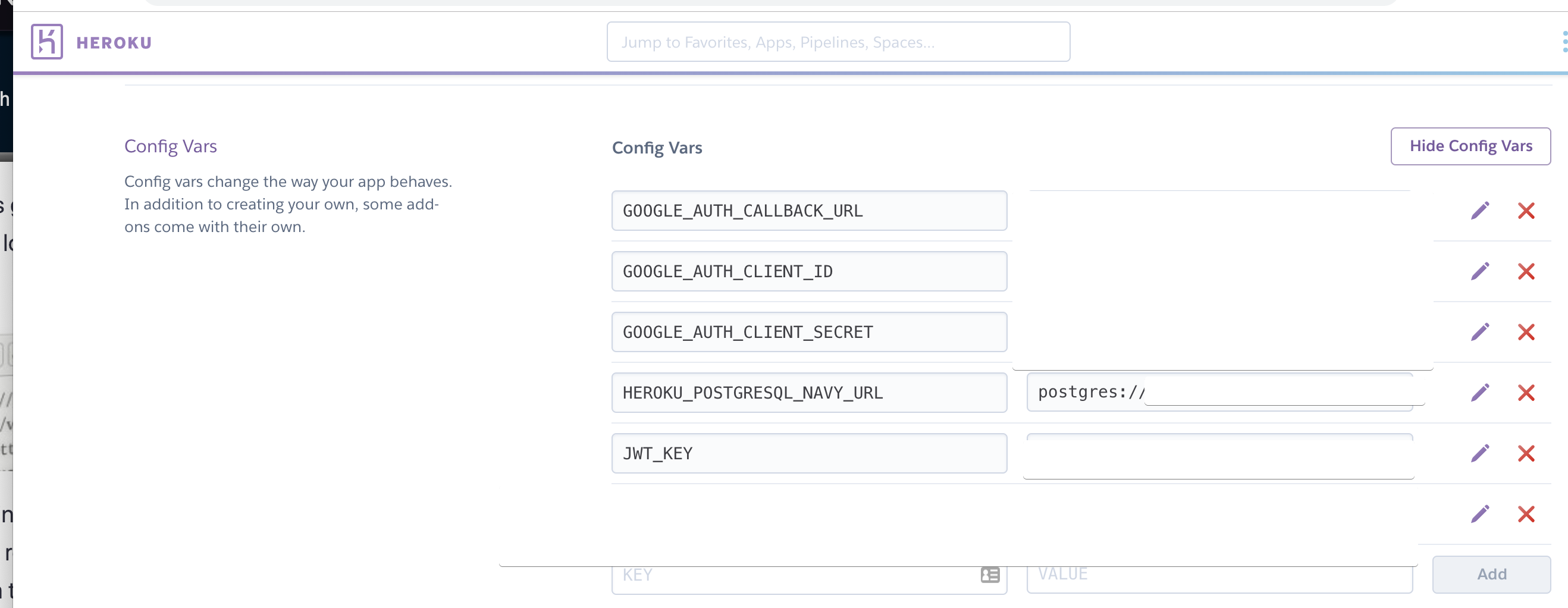
Node-config will pull Heroku's config vars in at run time. No need to handle multiple config injection logic. Set it once and it will all just work like magic!
Conclusion
I really like the combination of Node-config with Heroku. The hierarchy layering keeps things simple, even while Heroku is rotating security keys under you!
Bonus for Visual Studio Code users
I use vsCode for my development.
If you follow the defaults, the environment and
launch.json setup will look a lot like this:

launch.json, which is vsCode's run/debug config will look like this:
{
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "launch",
"name": "RUN DEV",
"program": "${workspaceFolder}/src/app.js",
"env": {
"NODE_ENV": "dev",
},
"outputCapture": "std"
},
{
"type": "node",
"request": "launch",
"name": "RUN PROD",
"program": "${workspaceFolder}/src/app.js",
"env": {
"NODE_ENV": "production",
},
"outputCapture": "std"
}
}
