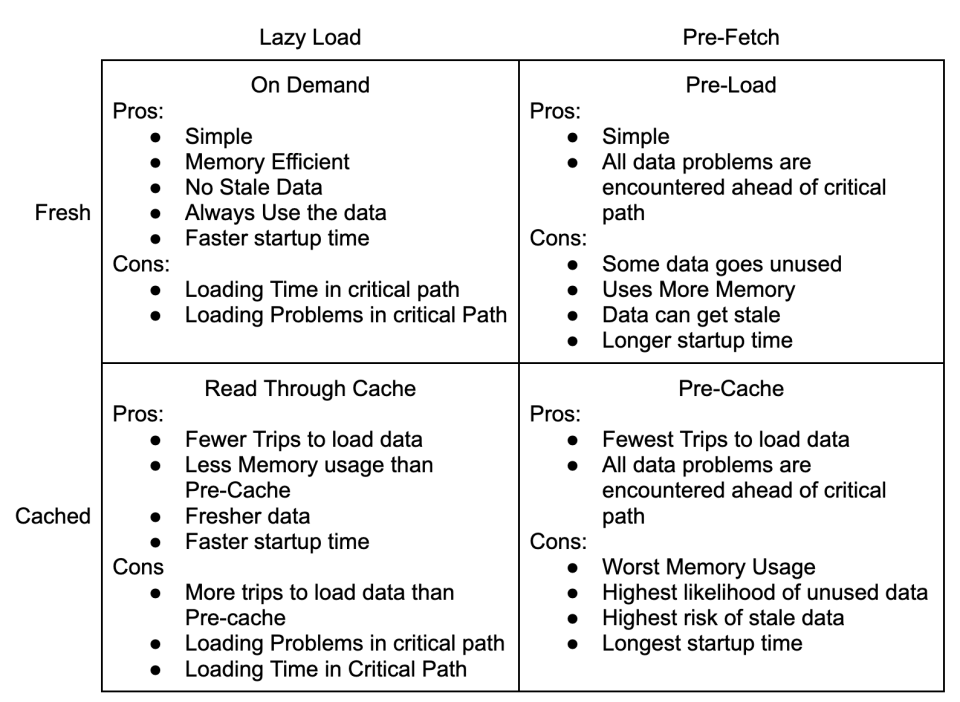
The Four Patterns Of Data Loading are about two main trade offs: simplicity for performance, and freshness for execution consistency.
This may seem odd because the quadrants are defined by loading and caching strategies, not simplicity, performance or execution consistency.
Simple or Performant
The decision to use caching is about trading simplicity for performance. You can simply load the data every time you need it. If you’re using MySql on AWS, a basic query will take about 2ms to return. The pattern is very simple and self contained: load data when needed.
Caching, saving data for reuse, improves performance by reducing the time it takes to use the data again. In exchange, you have to think about your code and determine:
- Will I use the data again?
- Is the data likely to change in the DB while I have it cached?
- If the data does change, do I want to use the latest version or the version that the process has been using so far?
- How much server memory will I need for the cache?
Example – Adding a Tag to a Contact
Imagine a simple operation, adding a tag to a contact. The tag is a string and the contact is represented by an email address. You need to transform the tag and email into ids and store them in a normalized database table. For simplicity’s sake, let’s say all DB operations take 2ms.
There are 3 DB Operations
- Load the contactId based on email
- Load the tagId based on tag
- Insert into contact_tags
With the On Demand access pattern, we do each action every time. This requires 3 trips to the DB for 6ms.
Similarly, with the Pre-Load pattern, we spend 2ms pre-loading the tagId, and each operation takes 4ms.
Using a Read Through Cache, we store the tagId after the first load. The first operation takes 6ms and each additional operation takes 4ms.
Finally, with the Pre-Cache pattern, we spend 2ms pre-loading the data and each operation takes 4ms.
| 1 Tag, 1 Contact | 1 Tag, 10 Contacts | 10 Tags, 10 Contacts | ||||
| Init | Exec | Init | Exec | Init | Exec | |
| On Demand | 0ms | 6ms | 0ms | 60ms | 0ms | 600ms |
| Pre-Load | 2ms | 4ms | 20ms | 40ms | 200ms | 400ms |
| Read Through Cache | 0ms | 6ms | 0ms | 42ms | 0ms | 420ms |
| Pre-Cache | 2ms | 4ms | 2ms | 40ms | 20ms | 400ms |
Freshness or Execution Consistency
The next tradeoff to consider the value of fresh data vs execution time consistency. This goes beyond questions of caching, it also affects whether you can use the Pre-Load strategy at all. A big advantage of the Pre-Load and Pre-Cache strategies is that the execution time is lower and less variable.
Stock trading software is designed to pre-load as much data as possible and can spend minutes initializing so that the actual buying and selling happens in microseconds. Similarly, internet ad networks like Google’s demand responses in 100ms or less. Having consistent execution times in each piece of your software makes it much easier to monitor performance for signs of trouble.
Security software and reporting sit on the other end of the spectrum. It doesn’t matter if a user had permission 5 minutes ago and everyone hates waiting for report data to update. In these cases the variance for each response is much less important than getting the most recent data.
Some data never changes once it has been created. In the example above of adding a tag to a contact, both tagId and contactId will never change during your program’s execution. Generally, anything with ‘id’ in the name is safe to cache. On the other hand counts, permissions, and timestamps change all the time.
Strategies can be good for some situations and terrible for others. Sometimes it depends on expectations vs money.
| Ids and static data | Permissions | Counts and Reporting | |
| On Demand | Bad | Good | Good, until it doesn’t scale |
| Pre-Load | Good | It depends on time elapsed | It depends on time and money |
| Read Through Cache | Good | It depends on time elapsed | It depends on time and money |
| Pre-Cache | Best | Bad | It depends on time and money |
Conclusion
The “right” data loading pattern is a moving target. Remember that in the beginning load is low and there are continuous changes. Simplicity is always a great choice when there isn’t enough scale to justify complexity.
As software matures two trade offs emerge: Simplicity vs Complexity and Freshness vs Consistency.
You’re changing the software for a reason. When you consider the tradeoffs it should become clear which patterns will help solve your problem.
1 comments On Tradeoffs with the Four Patterns Of Data Loading
Pingback: Patterns of Data Loading – With Messaging Queues – Sherman On Software ()