In my last article, You Won’t Pay Me to Rescue Your Legacy System, I talked about my original attempt at specializing, and why it didn’t work. I bumbled along until I lucked into a client that helped me understand when Legacy System Rescue becomes an Expensive Problem.
Rather than Legacy System Rescue, I was hired to do “keep the lights on” work. The company had a 3 developer team working on a next generation system, all I had to do was to keep things running as smoothly as possible until they delivered.
The legacy system was buckling under the weight of their current customers. Potential customers were waiting in line to give them money, and had to be turned. Active customers were churning because the platform was buckling.
That’s when I realized - Legacy System Rescue may grudgingly get a single developer, but Scaling gets three developers to scale and one to keep the lights on. Scaling is an expensive problem because it involves churning existing customers and turning away new ones.
Over 10 months I iteratively rescued the legacy system by fixing bugs and removing choke points. After investing over 50 developer months, the next generation system was completely scrapped.
The Lesson - Companies won’t pay to rescue a legacy system, but they'd gladly pay 4x to scaleup and meet demand.
For SaaS with a pure Single Tenant model, infrastructure consolidation usually drives the first two, nearly simultaneous, steps towards a Multi-Tenant model. The two steps convert the front end servers to be Multi-Tenant and switch the client databases from physical to logical isolation. These two steps are usually done nearly simultaneously as a SaaS grows beyond a handful of clients, infrastructure costs skyrocket and things become unmanageable.
Considering the 5 factors laid out in the introduction and addendum - complexity, security, scalability, consistent performance, and synergy this move greatly increases scalability, at the cost of increased complexity, decreased security, and opening the door to consistent performance problems. Synergy is not immediately impacted, but these changes make adding Synergy at a later date much easier.
Why is this such an early move when it has 3 negative factors and only 1 positive? Because pure Single Tenant designs have nearly insurmountable scalability problems, and these two changes are the fastest, most obvious and most cost effective solution.
Complexity
Shifting from Single Tenant servers and databases to Multi-Tenant slightly increases software complexity in exchange for massively decreasing platform complexity.
The web servers need to be able to understand which client a request is for, usually through sub domains like client.mySaaS.com, and use that knowledge to validate the user and connect to the correct database to retrieve data.
The difficult and risky part here is making sure that valid sessions stay associated with the correct account.
Database server consolidation tends to be less tricky. Most database servers support multiple schemas with their own credentials and logical isolation. Logical separation provides unique connection settings for the web servers. Individual client logins are restricted to the client’s schema and the SaaS developers do not need to treat logical and physical separation any differently.
Migrations and Versioning Become Expensive
The biggest database problems with a many-to-many design crop up during migrations. Inevitably, web and database changes will be incomparable between versions. Some SaaS models require all clients on the same version, which limits comparability issues to the release window (which itself can take days), while other models allow clients to be on different versions for years.
The general solution to the problem of long lived versions is to stand up a pool of web and database servers on the new version, migrate clients to the new pool, and update request routing.
Security
The biggest risk around these changes is database secret handling; every server can now connect to every database. Compromising a single server becomes a vector for exposing data from multiple clients. This risk can be limited by proxy layers that keep database connections away from public facing web servers. Still a compromised server is now a risk to multiple clients.
Changing from physical to logical database separation is less risky. Each client will still be logically separated with their own schema, and permissioning should make it impossible to do queries across multiple clients.
Scalability
Scalability is the goal of Multi-Tenant Infrastructure Consolidation.
In addition to helping the SaaS, the consolidation will also help clients. Shared server pools will increase stability and uptime by providing access to a much larger group of active servers. The client also benefits from having more servers and more slack, making it much easier for the SaaS to absorb bursts in client activity.
Likewise, running multiple clients on larger database clusters generally increases uptime and provides slack for bursts and spikes.
These changes only impact response times when the single tenant setup would have been overwhelmed. The minimum response times don’t change, but the maximum response times get lower and occur less frequently.
Consistent Performance
The flip side to the tenancy change is the introduction of the Noisy Neighbor problem. This mostly impacts the database layer and occurs when large clients overwhelm the database servers and drown out resources for smaller clients.
This can be especially frustrating to clients because it can happen at any time, last for an unknown period, and there’s no warning or notification. Things “get slow” and there are no guarantees about how often clients are impacted, notice, or complain.
Synergy
There is no direct Synergy impact from changing the web and database servers.
A SaaS starting from a pure Single Tenant model is not pursuing Synergy, otherwise the initial model would have been Multi-Tenant.
Placing distinct client schemas onto a single server does open the door to future Synergy work. Working with data in SQL across different schemas on the same server is much easier than working across physical servers. The work would still require changing the security model and writing quite a bit of code. There is now a doorway if the SaaS has a reason to walk through.
Conclusion
As discussed in the introduction, a SaaS may begin with a purely Single Tenant model for several reasons. High infrastructure bills and poor resource utilization will quickly drive an Infrastructure Consolidation to Multi-Tenant servers and logically separated databases.
The exceptions to this rule are SaaS that have few very large clients or clients with high security requirements. These SaaS will have to price and market themselves accordingly.
Infrastructure Consolidation is an early driver away from a pure Single Tenant model to Multi-Tenancy. The change is mostly positive for clients, but does add additional security and client satisfaction risks.
Intractable technical problems are a fact of life. Architectures make seemingly easy use cases impossible. Critical code won’t scale, because of meaningless choices made years ago. There are endless tech problems that defy easy and obvious solutions.
Earnest, well meaning, developers who come up with solutions that won’t work are also part of life.
After you’ve been thinking about a problem for months or years it can be tempting to tell a developer why their solutions won’t work. Lead the developer down your chain of reasoning. Show them how much more you’ve thought about the problem. How you’ve considered their solution, and a dozen others. Be superior and dismissive.
Prove that the intractable problem can’t be solved until you get the developer to say “Ok! Ok! You’re right! It won’t work!”
Or, you could be open to being wrong and build an ally.
Agree with the basic idea of the solution. That seemed like a good idea to you too! Then, instead of telling them why they can’t, ask the developer how they got around the intractable problem.
“How did you solve it?” is interested and hopeful. It tells the other person “I have spent time thinking about this problem too. Here’s where I got stuck. I’d love to hear how you think we can solve this problem.”
There’s almost never a solution. Most of the time the other person had no idea that the architecture wouldn’t support it, that the message size is too big, or any of the subtle technical reasons why the solution won’t work.
Asking about the solution, instead of preaching the problem, puts the two of you on the same side. It makes you allies against the problem and sidesteps the teacher/student power dynamic of “That won’t work.”
Sometimes, a fresh perspective does produce a solution to the intractable problem. Since you avoided staking a claim that there was no solution, you won’t feel the sting of being wrong. You won’t end up defensive, and can embrace the developer’s solution.
“How did you solve it” builds allies. “That won’t work” harms you both.
Starting next week I will have new content every week, mostly on Wednesdays.
This blog covers scaling SaaS software: common gotchas, anti-patterns, performance and scaling strategies. I cover the technical and social aspects of these problems because it is often harder to convince people than implement code.
This is a short and sweet post to remind you of who I am, what to expect from this blog, and test to see if everything is still working.
I'm Jeffrey Sherman, and this blog is about software performance and scaling. Along the way I'll also talk a lot about development team management, which is often far more important and more effective than writing code.
My current goal is to publish one article per week, mostly on Wednesday.
If that sounds good you should absolutely subscribe to get this blog as an email. For those who have already subscribed, thank you for letting me into your inbox!
To paraphrase Charles Babbage: Racism In, Racism Out. When your inputs are racist, your outputs will be racist. Even if you didn’t do anything racist.
Years ago, I worked for one of the largest residential mortgage brokers in the US and often tried to impress upon my fellow developers the need to be aware of the past so that we could try to reduce the racism flowing through our code.
The conversations were usually flat. They would thank me for the interesting history lesson and walk away assured that since they weren’t racist, and weren’t coding anything racist, there was no racism in the software.
Housing in the US has a long and sored history of racism.
Here are two quick examples of how race and racism leaks into mortgage software. The first is pretty blunt, the second is subtle.
Colorblind Code Not Allowed
For residential mortgages, the US Government requires asking borrowers race and gender. The government uses the data to find racism (and sexism) in lending. This data is how we know that Black borrowers pay higher rates and get rejected for loans more often. The data paints a depressing picture, racism is prevalent in the mortgage industry. You have to add race to your code, and it is a good bet that some of your users will exploit that data to discriminate.
Pricing Is Based Off Racist History
As a part of the appraisal process, the appraiser will find “comparable” houses nearby to validate the price. In areas where the value of homes has been depressed by racist history like redlining, comparables act as a racist anchor. Using comparables is like saying “houses in this neighborhood are worth less than other neighborhoods because 60 years ago racists decided that predominantly Black neighborhoods are worth less, and we have decided to continue the process.”
Many states ban asking about salary history because it reinforces past discrimination. There are companies out there pushing back against the use of comps. As a developer you won’t be able to choose the company’s risk models, but with a little work, you can code up alternative models and make better data available.
Don’t be Passive
You have an obligation to understand your inputs. You may not be able to sanitize them, but understanding is a vital first step. Google the history of your industry to find where racism has come from in the past, and think about how your code makes it easier or harder for history to repeat itself.
When designing a system, what are the differences between bidirectional links and tags?
Tags build value Asynchronously
The most obvious difference is that tags are asynchronous and become more useful as tags are added. Tags can return results with as few as 1 member, and grow over time. Links require two items, can’t be set until both items exist, and will never contain more than the two items.
Links are static, while Tags are living documents. Links will be the same when you come back to them, tags will be different over time.
Tags are Clusters, Links are Paths
Tags can quickly provide a cluster of related items, but don’t offer guidance over what to read next. Links highlight related, highly branching items. Readers can swim in a pool of tags, or follow a path of links.
Tags are great if you want more on the topic, links help you find the next topic.
Links are Curated
To create a link, you have to know that the other item exists. Your ability to create links will always be constrained by your knowledge of previously published items, or your time and desire to search out related content. Tags are a shot in the dark. They work regardless of your knowledge of the past. As a result, links are a more curated source.
Tags are Context
Tag names are context. If you add a “business” tag to a bunch of articles, someone else will know why you grouped the articles together. Links do not retain any context, later users (including yourself in 6 months) will need to examine both items to know why you linked them.
Bidirectional Links are more DB Intensive
Assuming your database is set up something like this:
Bidirectional links require 2 rows for each entry.
Tags require 1 row per entry plus 1 row for the tag.
Big O says that 2N and N + 1 are both O(n). Anyone who has worked on an overwhelmed database will tell you that 2 insertions can be way more than twice as expensive as 1.
Conclusion
As a practical matter, tags are more friendly to casual content creation and casual users.
Links are better when created by subject matter experts and consumed by people trying to learn an entire topic.
The Strangler is an extremely effective technique for phasing out legacy systems over time. Instead of spending months getting a new system up to parity with the current system so that clients can use it, you place The Strangler between the original system and the clients.
The Strangler passes any request that the new system can’t handle on to the legacy system. Over time, the new system handles more and more, the legacy system does less and less. Most importantly, your clients won’t have to do any migration work and won’t notice a thing as the legacy system fades away.
A common objection to setting up a Strangler is that it Yet Another Thing that your overloaded team needs to build. Write a request proxy on top of rewriting the original requests! Who has time?
Except, AWS customers already have a fully featured Strangler on their shelf. The Elastic Load Balancer (ELB) is a tool that takes incoming requests and forwards them on to another server.
The only requirement is that your clients access your application through a DNS name.
With an afternoon’s worth of effort you can set up a Strangler for your legacy application.
You no longer need to get the new system up to feature parity for clients to start using it! Instead, new features get routed to the new server, while old ones stay with the legacy system. When you do have time or a business reason to replace an existing feature the release is nothing more than a config change.
Getting a new system up to parity with the legacy system is a long process with little business value. The Strangler lets your new system leverage the legacy system, and you don’t even have to let your clients know about the migration. The Strangler is your Best Alternative to a Total Rewrite!
Do they know the frustrating pain of needing features that can’t be delivered? The maddening pain of redoing work destroyed by a bug? The teeth grinding pain of slow systems that steal minutes with deadlines hours away?
Which pains are they addressing, and how much of the system do they need to rewrite to give clients some relief?
Pain provides focus and a metric for success. Without a specific pain goal, the project will metastasize and grow into “replace everything”.
How will you support current users during the rewrite?
Feature freeze is the most common answer, but it should not be acceptable. Neither is only patching critical bugs.
One solution that has worked well for me: The Senior proposing the rewrite gets to architect and oversee the new solution, but all the coding will be done by the juniors. The senior will be responsible for fixing bugs and implementing new features on the legacy system.
With that much skin in the game, and no juniors doing junior things, you’ll be amazed at how quickly the legacy system stabilizes. I have seen this be so successful that the rewrite gets canceled, and the work written off as a moral boosting learning experience.
What lessons have you learned from the original system, and how will you prevent repeating the same mistakes?
This is really a question of ownership. Are your developers ready to acknowledge and own their mistakes?
Are their expectations for the future realistic, or do they expect the shiny new technology to prevent them from making the same mistakes?
Going from monoliths to micro services, micro services to serverless, or serverless back to a monolith won't help if your developers are repeatedly implementing a fundamentally flawed design.
Rewrites can destroy your company
Companies have been destroyed by endlessly stalled rewrites.
Work with your developers to answer these questions. It’s likely that you’ll find a much less risky path than the full rewrite. If you do agree to the rewrite, asking questions will give you confidence that your developers have a realistic plan that they can deliver.
Here are six questions to ask yourself, or a developer, before dancing to the automation music:
How often is the task likely to change?
Weekly Business Intelligence reports change monthly, monthly ones change every quarter, and quarterly ones change every year. They are never stable enough to be worth automating by an outside developer. This is why BI tools that let non-technical users semi-automate reports are a 5 billion dollar industry.
On the other hand, regulatory and compliance reports are likely to be stable for years and make great targets.
If a task won’t be executed at least 10 times between changes, it probably won’t be worth automating.
How long is the task likely to continue?
Some tasks are likely to continue “forever”. Archiving old client data, scrubbing databases and other client onboarding/offloading tasks fall into this category.
Some tasks are never going to come up again.
If a task won’t be executed at least 5 more times, it probably won’t be worth automating.
How much human effort does the task consume, and for whom?
You can automate turning on the office lights in the morning with a motion detector, but it won’t pay off in terms of time saved from flipping a switch.
How much of an interruption is doing the task? Turning on the lights on your way in the door isn’t an interruption for anyone. Phone support manually resetting a user password isn’t an interruption, but having the CFO process refunds for clients is a giant interruption.
Even if the reset and refund are both a single button click that takes 15 seconds, pulling the CFO away is a much bigger deal. Also the context switch for the CFO will be measured in minutes because she’s not processing refunds all day long.
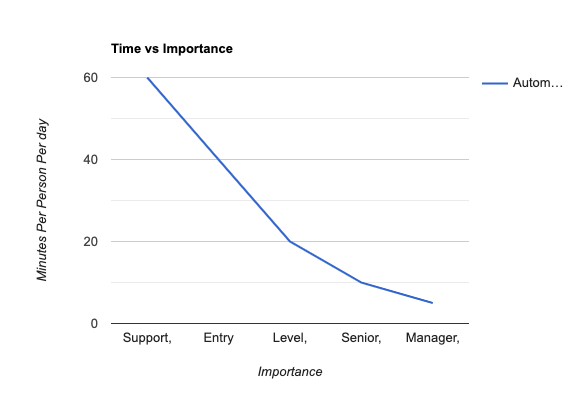
Use a sliding scale based on time and title. For entry level, don’t automate until the task takes more than an hour per person per day. For the C-Suite anything over 5 minutes per day is a good target.
How much lag can automation save your clients?
Clients don’t care how long the task takes, they care about the lag between asking and receiving. It doesn’t matter that processing a refund only take 5 minutes if your team only processes refunds once a week.
If the client lag is more than a day, consider automating.
Is the Task a real process, or are you cleaning up the effects of a bug?
Software bugs can do all sorts of terrible things to your data and process, but after the first couple of times, the damage becomes predictable and you’ll get better at fixing the damage.
Automating the fix is one way of fixing the bug. That’s how bugs become features.
If you don’t want to make the bug an official part of your software, don’t automate the fix.
How common and expensive are mistakes?
Mistakes are inevitable when humans are manually performing routine tasks.
Mistakes are inevitable when developers first automate a routine task. Assume that developer mistakes will equal one instance of a manual mistake.
For an automation to save money you have to expect to prevent at least 2 manual errors.
As an equation:
[Cost to Automate] + [Cost of a mistake] < [Cost of a mistake] * [Frequency of mistakes]
Because the cost of mistakes is relatively easy to quantify, tasks with expensive mistakes are usually automated early on.
Conclusion
Developers always want to automate things, sometimes it pays off, sometimes it’s a mistake.
If you ask these six questions before automating you’re much more likely to make the right choice:
How often is the task likely to change?
How long is the task likely to continue?
How much human effort does the task consume, and for whom?
How much lag can automation save your clients?
Is the Task a real process, or are you cleaning up the effects of a bug?