In service oriented architectures adding new application settings like environment variables, constants, and feature flags costs almost nothing. Cleaning them up, however, is expensive.
Ideally developers would keep track of settings and remove them when they are no longer needed. More often feature flags get set to 100%, everyone moves on, and the old code path lingers for months. I have personally spent hours updating code, only to realize that it is effectively unreachable and needs to be deleted instead.
Talk about wasting time and money!
The High Cost of Doing Nothing
Doing nothing seems like a cheap solution. The code gets a little bloated, the services use a little more memory, and API calls send a few extra kilobytes. No single unused feature flag or environment variable has any impact.
Eventually you end up with hundreds of unused settings, on thousands of servers, distributed to hundreds of thousands of customers.
The cost of those crufty settings add up in terms of performance, development time, and outages.
Cutting Cruft Is Expensive Too
A key disadvantage of Service Oriented Architecture is that settings get passed from one service to the next. It’s rarely safe to remove unused settings because they may be gathered into a collection and passed along to a service that does use them.
Figuring out what is used where across multiple services is a slow process. When you’ve got hundreds of settings to investigate, it’s daunting and demoralizing.
A Very Basic Garbage Collector
A Garbage Collector keeps track of references to objects, and when there are no more references, cleans them up.
You can make a very basic collector by scripting out a few API calls to your git repository.
The three basic steps are:
Download and parse the constants file(s) from the parent app and extract a list of settings names
Make API requests against your git vendor searching for the strings
For each setting name make a file which lists which repo the string appears in
That’s it! You now have a rudimentary system that tracks references to settings across your repos. Any setting file with only one entry isn’t used anywhere else and can be deleted once the parent app is done with it.
Conclusion
A garbage collector is overkill if you’re curious about a handful of settings, just use regular search. But when you’re facing hundreds of settings and you need to figure out which can be targeted for cleanup, a garbage collector might be just what you need.
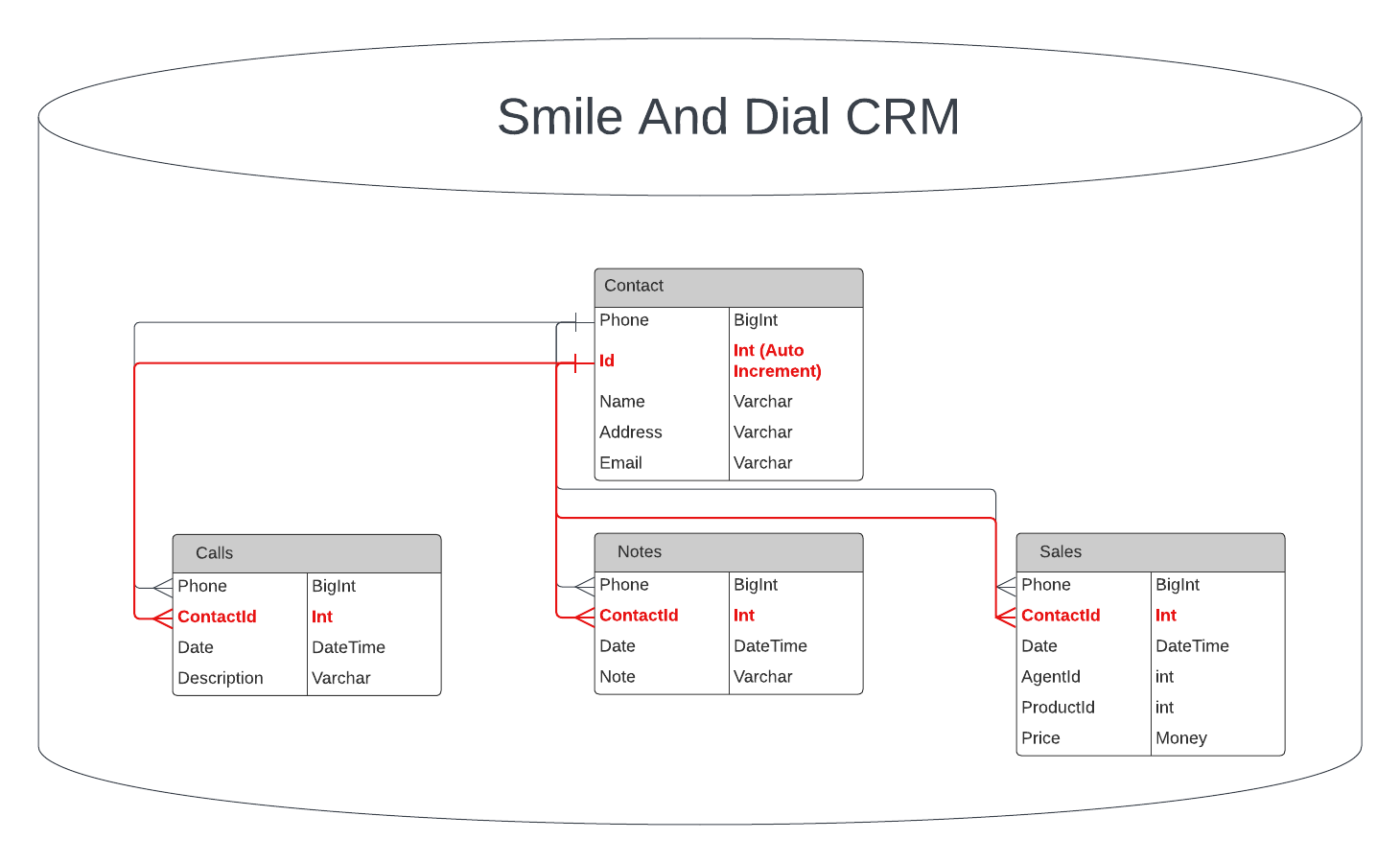
Onward with SmileAndDial CRM, and their quest to remove phone numbers as a fundamental constraint! Part 2 introduced the concept of TheeSeeShipping, a low risk, iterative way to make large sweeping changes. At the end of part 2, the database looked like this:
New Id columns have been added, but they are unused and null.
Now SmileAndDial’s developers can TheeSeeShip small, incremental, low risk changes to production. These changes are invisible to users and can be worked in with day-to-day work.
TheeSeeShipping works like a ratchet; once a change is complete, it stays complete. Whether the work is done quickly or slowly, change is inexorable and one way.
The Second Series of Releases - Propagating ContactId
The second series of releases is to insert the new Contact.Id value into other tables’ ContactId value when rows are inserted.
This requires lots of small changes - getting the new Id after inserting into Contact and adding it to the insert statement in other tables. But, because the fields are nullable, there are no foreign keys, and no query logic; these changes can be done incrementally.
Fix one or two inserts every release. These are small, easily testable changes. Grab the Id, add it to the insert, confirm that the row was written with the correct ContractId.
TheeSeeShip it in low risk, two line changes until all new rows have a ContactId.
The next step in this series is to backfill the existing data. The Contact table has an Id for all rows. Run an update query for each table to backfill the data.
Guess what, since the data still isn’t used in the system this is also a low risk query.
Now every row in the database has a value for ContactId, and every new row will get a value on insert. The time has come to remove the nullability and add in the foreign keys.
The Third Series of Releases - Updating Selects
With ContactId propagated to every table in the database, the time has come to update the Select queries. Instead of selecting from every table by phone number, SmileAndDial needs to run off of ContactId, or join Contact to use Phone
Each of these changes can be made incrementally in a separate release. They are small, easy to test, and independent of each other. TheeSeeShip it; the data model is different, but to customers it is still SmileAndDial.
After any bugs or missing ContactIds get fixed, it is time to remove the foreign key constraint on the Phone field. Note that this can be done at any time that is convenient to the DB team. There’s no rush and no impact if a bug with ContactId does turn up.
The Fourth Series of Releases - Removing the Fundamental Constraint
Everything in the first three series of releases was incremental and non-breaking. Each change was minimal and non-breaking.
Even at the end of phase 3, the discovery of an unmodified table would have no impact on the system. The table and code would continue to work as it always had. Any mistakes were easy to roll back.
Everything had changed, and everything was still the same.
In the fourth series of iterations, Email will be removed as a fundamental constraint in the system. This, finally, is a breaking change that is not trivial to undo.
But, it is also a change that is easy to do in an incremental, low risk way.
Incrementally remove the Phone column from all tables except for Contact. At this point there are no foreign relations or Select statements that use Phone.
Finally, when Phone is gone everywhere else, make Contact.Phone nullable. Update the service and UI logic to allow the creation of a contact without a phone number.
Phone Is No Longer Fundamental
There are a lot of incremental changes and releases in the four series. The key is that each change was very small and very low risk. After each release customers had a fully functional, up to date, version of SmileAndDial.
Unreleased work in progress was low and work could have halted for months at a time without any of the completed work suffering from code rot.
TheeSeeShipping changed the fundamental nature of SmileAndDial without ever taking SmileAndDial out of the hands of its customers.
Part 2 covers how NoSQL emerged as an improvement over the classic relational database solution for User Defined Fields. NoSQL delivers speed and scalability by being expensive and fragile. In part 3 I’m going to cover the emerging Hybrid Database solution for User Defined Fields.
Hybrid Databases allow you to combine the best aspects of the relational and NoSQL models, while avoiding most of the downsides.
A hybrid implementation looks like this:
The hybrid model brings the data back to a single server, but without the Contact->Field relation. Instead the field data is stored as a JSON object in the Contact table itself.
Pros:
No meta programming and no filters, everything is back to SQL. Hybrid databases allow you to directly query JSON fields as if they were regular columnar fields.
You can create indexes on the JSON data. This is an improvement over both the classic and NoSQL models. It can significantly improve performance by allowing the database engine to optimize queries based on usage.
Having a single system makes things simple to set up and easier to maintain.
The database will enforce valid JSON structures, which makes it difficult to poison your data.
Cons:
There’s no enforced relationship between the JSON data and your User Defined Fields. This means that data can get lost because your system no longer knows to display or delete it.
While Hybrid Databases should scale far beyond the needs of your SaaS, the scaling isn’t quite as open ended as the NoSQL model. If you out-scale the Hybrid model, congratulations, your company’s services are in high demand!
Conclusion
If your SaaS is implementing User Defined Fields from scratch today, go with the Hybrid model. If you already have the classic or NoSQL pattern in place, it’s a good time to start thinking about how to evolve towards a hybrid solution.
I’ll cover how to evolve your existing solution in Part 4.
In part 1 - I covered the classic solution for User Defined Fields; simple but unscalable.
NoSQL emerged as a solution to relational fields in the late 2000s. Instead of having a meta table defining fields in a relational database, the User Defined data would live in NoSQL.
The structure would look like this:
This model eliminates the meta programming and joining the same table against itself. The major new headache that this model creates is difficulty in maintaining the integrity of the field data.
Pros:
No complicated meta programming. Instead you write a filter/match function to run against the data in the Collection Of Fields.
No more repeated matching against the same table. Adding additional search criteria has minimal cost.
Open ended/internet level scaling. For a CRM or SaaS, the limiting factor will be the cost of storing data, not a hard limit of the technology.
Cons:
Much more complicated to set up and maintain. Even with managed services supporting two database technologies doubles the difficulty of CRUD. Multiple inserts, multiple deletes, tons of ways for things to go wrong.
Without a relational database enforcing the data structure, poisoned or unreadable data is common. Being able to store arbitrary data collections means you’ll invariably store buggy data. You’ll miss some records during upgrades and have to support multiple deserializers. You will lose customer data in the name of expediency and cost control.
It’s more expensive. You’ll pay for your relational database, NoSQL database, and software to map between the two.
Conclusion
NoSQL systems solve the scaling problems with setting up User Defined Fields in a relational database. The scaling comes with high costs in terms of complexity, fragility and costs.
Reducing the complexity, fragility, and costs leads to the upcoming 3rd shift, covered in part 3.
This series covers a brief history of the 2 historic patterns for implementing User Defined Fields in a CRM, the upcoming hybrid solution that provides the best of both worlds, and how to evolve your existing CRM to the latest pattern. If you care about CRM performance, scaling, or cost, this series is for you!
What are User Defined Field Patterns?
Every CRM provides a basic fields for defining a customer. Every CRM’s basic field set is different depending on the CRM’s focus. So, every user of a CRM needs to expand the basic definition in some way. Birthdays, purchase history, and interests are three very common additions.
The trick is allowing users to define their own fields in ways that don’t break your CRM.
The Three Patterns
At a high level, there have been three major architectures for implementing Custom Fields. Most of the design is driven by the strengths and weaknesses of the underlying database architecture.
Pattern 1, generalized columns in a database, spanned the dawn of time until the rise of NoSQL around 2010.
Pattern 2, NoSQL, began around 2010 and continues to today.
Pattern 3, JSON in a relational database, began in the late 2010s and combines the best of the two approaches
Pattern 1 - All in a Relational Database
Before the rise of NoSql there was pretty much one way to build generic user defined fields.
The setup is simple, just 3 tables. A table of field definitions, a table for contacts, and a relational table with the 2 ids and the value for that contact’s custom field.
The Pros
This design is extremely simple and can be implemented by a single developer very quickly.
Basic CRUD operations are easy and efficient.
The Cons
Building search queries requires complicated techniques like metaprogramming.
Every search criteria results in a join against the ContactFields table. This results in an exponential explosion in query times.
The lack of defined table columns handicaps the database’s query optimization strategies.
Conclusion
The classic relational database pattern is easy to set up, but has terrible scaling. This super simple example would bog down by 1,000 contacts and 50 fields.
There are lots of ways to redesign for scale, but this is a SHORT history. Suffice it to say that it takes extremely complex and finicky systems to scale past 100,000 contacts and 1,000 fields.
The solutions to the classic pattern’s scaling led to the NoSQL revolution, covered in part 2.
You become a Scaleup when your SaaS’s service offering becomes compelling and you start attracting exponentially more clients.
All at once you have a lot more clients, clients with a lot more data.
Solutions that support 1,000 clients buckle as you pass 5,000. Suddenly, 25,000 clients is only months away.
Services that support hundreds of thousands of transactions a day fall hopelessly behind as you onboard clients with millions of transactions.
You finally know what customers want. You quickly find the edges of your system. Money is rolling in from customers and VCs. You can throw money at the problems to literally buy time to find a solution.
But you’re faced with a looming question - moonshots or baby steps.
Moonshots Are About You, Baby Steps Are About Your Clients
It’s not about you or your SaaS, it’s about your client’s outcomes.
Moonshots are appealing because they take you directly to where you need to be. Your system needs to scale 10x today and 100x next year; why not go straight for 100x?
Baby steps feel like aiming low because the impact on you is small. But it’s not about you! Think about the impact on your clients.
From a technology perspective, sending emails 1% faster is ::yawn::
But for your clients, faster emails means more engagement, which means more sales.
Would your clients rather have more sales this week, compounding every week for the next year, or flat sales for a year while you build a moonshot?
Clients who churn, or go out of business, won’t get value from the moonshot. Even if you deliver greater value eventually, your clients are better off getting some value now.
Are you delivering value to your SaaS or your clients?
The Chestburster is an antipattern that occurs when transitioning from a monolith to services.
The team sees an opportunity to exact a small piece of functionality from the monolith into a new service, but the monolith is the only place that handles security, permissions and composition.
Because the new service can’t face clients directly, the Chestburster hides behind the monolith, hoping to burst through at some later point.
The Chestburster begins as the inverse of the Strangler pattern, with the monolith delegating to the service instead of the new service delegates to the monolith.
Why it’s appealing
The Chestburster’s appeal is that it gets the New Service up and running quickly. This looks like progress! The legacy code is extracted, possibly rewritten, and maybe better.
Why it fails
There is no business case for building the functionality the new service needs to burst through the monolith. The functionality has been rewritten. It's been rewritten into a new service. How do you go back now and ask for time to address security and the other missing pieces? Worse, the missing pieces are usually outside of the team’s control; security is one area you want to leave to the experts.
Even if you get past all the problems on your side, you’ve created new composition complexities for the client. Now the client has to create a new connection to the Chestburster and handle routing themselves. Can you make your clients update? Should you?
Remember The Strangler
If you want to break apart a monolith, it’s always a good idea to start with a Strangler. If you can’t set up a strangle on your existing monolith, you aren’t ready to start breaking it apart.
That doesn’t mean you’re stuck with the current functionality!
If you have the time and resources to extract the code into a new service, you have the time and resources to decouple the code inside of the monolith. When the time comes to decompose into services, you’ll be ready.
Conclusion
The chestburster gives the illusion of quick progress; but quickly stalls as the team runs into problems they can’t control. Overcoming the technical hurdles doesn’t guarantee that clients will ever update their integration.
Success in legacy system replacement comes by integrating first, and moving functionality second. With the chestburster you move functionality first and probably never burst through.
Over the past few months I have been ruminating on SaaS Tenancy Models and how they drive architectural decisions. I hope you’ve enjoyed the series as I’ve scratched my itch.
Here is a roundup of the 7 articles In case you missed any of the parts, or need a handy index to what I’m sure is the most in depth discussion of SaaS Tenancy Models ever written.
3 Signs Your Resource Allocation Model Is Working Against You
After 6 posts on SaaS Tenancy Models, I want to bring it back to some concrete examples. When your SaaS has a Single Tenant model, clients expect to allocate all the resources they need, whenever they want. When every client is entitled to the entire resource pool, no client gets a great customer experience.
Here are 3 signs your Resource Allocation Model is working against you:
Large clients cause small client’s work to stall
You have to rebalance the mix of clients in a cell for stability
Run your job at night for best performance
Large clients cause small client’s work to stall
This is a classic “noisy neighbor” problem. Each client tries to claim all the shared resources needed to do their work. This isn’t much of a problem when none of the clients need a significant percentage of the pool. When a large client comes along, it drains the pool, and leaves your small clients flopping like fish out of water.
You have to rebalance the mix of clients in a cell for stability
When having multiple large clients in a cell affects stability, the short term solution is to migrate some clients to another cell. Large clients can impact performance, but they should not be able to impact stability. Moving clients around buys you time, but it also forces you to focus on smaller, less profitable clients.
Run your job at night for best performance
This is advice that often pops up on SaaS message boards. Don’t try to run your job during the day, schedule it to run in the evening so it is ready for the morning. When clients start posting workarounds to your problems, it’s a clear sign of frustration. Your clients are noticing that performance varies by the time of day. They are building mental models of your platform and deciding you have load and scale issues. By being helpful to each other, your clients are advertising your problems.
A Jobs Service is a very common service for SaaS companies. It provides a way to run work on a schedule, on demand, and independent of human activity. Often, everything that isn’t done through the website is done by a Job Service.
I have never worked at a SaaS without some version of a Job Service, usually homegrown and built off a database instead of a queue. They usually have descriptive and funny names - Task Processor, Crons, Crontabulous, Maestro, Batch Processor and of course Polite Batch Jobs.
Starting early in the SaaS’s life, they also evolve and grow with the SaaS, creating problems as they migrate from Single Tenant to a logically shared environment.
Single Tenant Job Service
In a single tenant model, provisioning a Job Service with a pool of workers is fairly straightforward. Jobs are generated and put onto a queue (and not a database!)
The Job Service takes jobs off of the queue and fans them out to the worker pool. This is simple and works well because the Queue handles the complexities of tracking and retrying jobs.
Multiple clients exist on a single database cluster, each with their own logically separate schema.
The CRUD service has become a pool of servers that can act on behalf of any client.
There is still only 1 queue and 1 Job Service; Workers can act on behalf of any client, just like the CRUD servers.
Jobs get added haphazardly, and processed in a FIFO manner.
This model is much more resource efficient - sharing workers allows you to size the pool to keep things busy.
But this design is a disaster from a Noisy Neighbor standpoint.
Because the Queue is FIFO, the Job Service has no visibility into the client composition of the pending jobs, and a large client can easily starve a small one of resources by adding hundreds or thousands of jobs to the queue. The large client will see progress as the jobs are processed, but nothing happens for the small client until the large job finishes.
Things get even worse if the Queue and Job Service are Global instead of Cell based. A global queue feeding a global worker pool that works on clients spread across multiple database clusters will naturally cause database cluster hot spots. Performance will degrade for everyone on the cluster while the workers do massive jobs for a few large clients.
You can add bandaids like limiting the number of jobs per client and moving excess work onto overflow queues. This will help smaller clients somewhat, but natural hotspots will still occur.
Cross The Tenancy Line - Become Multi-Tenant
The Job Service needs to evolve from being Logically Separated into a Multi-Tenant service.
It needs to know how many jobs each client has pending, how long the jobs are taking, and how hot the database clusters are running so that it can operate a priority queue instead of FIFO.
The Jobs Service needs to move across the Tenancy Line
What is the Tenancy Line?
With Logically Separate infrastructure the clients share infrastructure, but the data and services all behave as if there is only one client at a time. As a result each client can regulate its own behavior, but has no visibility into the infrastructure as a whole.
To stop acting like a Single Tenant service, the Jobs Service needs to cross the line into Multi-Tenancy.
This change is conceptually simple, but has a lot of subtle implications.
The Service can control load across clients
In the original model work loads are random based on when jobs are added to the queue. When a hotspot emerges, there’s not much that the service can do without manual intervention. When there’s a noisy neighbor you can’t do much to stop them from starving smaller clients because you don’t know where those clients are in the queue.
With a Multi-Tenant job service, you can control resources across cells and the entire platform. Small clients can be protected by moving jobs up in priority based on how many recent jobs they have completed.
Jobs will finish faster as worker loads can be managed across cells, preventing hotspots.
Overall throughput will rise, smaller client performance will improve dramatically, and large clients will see more consistent execution times.
The Job Service Becomes a Queue
The original design used a single simple queue. Every client adds jobs directly to the queue, and the Job Service’s responsibility is to take work, pass it to a worker, and mark the job as complete. If there’s a failure, the queue will time the job out and put the work back on the queue.
A FIFO queue prioritizes by insertion order and doesn’t have any mechanism for reordering. The Job Service will have to build prioritization logic and find a way to integrate into a queuing mechanism. Do not give in to temptation and turn your database into a queue!
Conclusion
Pushing the Jobs Service across the Tenancy Line is a major coming of age step in the evolution of a SaaS company.
It trades significant development resources and complexity for consistent execution and a solution to the Noisy Neighbor Problem. The SaaS benefits from the synergy this creates with better resource utilization and reduced database hotspotting.
Once a SaaS has enough clients to warrant the change, making the Jobs Processor Multi-Tenant is a major step forward.